Kotlin/JVM 编译流程浅析
一般的编译流程
编译器一般由以下几个部分组成:
- 词法分析器(Lexical Analyzer):也称为扫描器(Scanner),它负责将源代码转化为一系列的记号(tokens)。每一个记号代表源代码中的最小有意义单元,如关键字、标识符、操作符、分隔符等。
- 语法分析器(Syntax Analyzer):也称为解析器(Parser),它根据词法分析器生成的记号,按照一定的语法规则生成语法树(或称为解析树)。语法树表达了输入程序的语法结构。
- 语义分析器(Semantic Analyzer):在这一步,编译器检查语法树中是否存在语义错误,比如类型检查、作用域检查等。语义分析可能会生成某种形式的中间表示(Intermediate Representation, IR)。
- 中间代码生成器(Intermediate Code Generator):将高层的源代码转换为较低层的、机器无关的中间代码。这种中间代码便于优化和翻译成机器码。
- 代码优化器(Code Optimizer):对中间代码进行优化,目的是提高程序的执行效率或减少代码的占用空间。优化方法包括移除无用代码、进行常量传播、循环优化等。
- 目标代码生成器(Code Generator):将优化后的中间代码转换为目标机器代码或汇编代码(assembly code)。
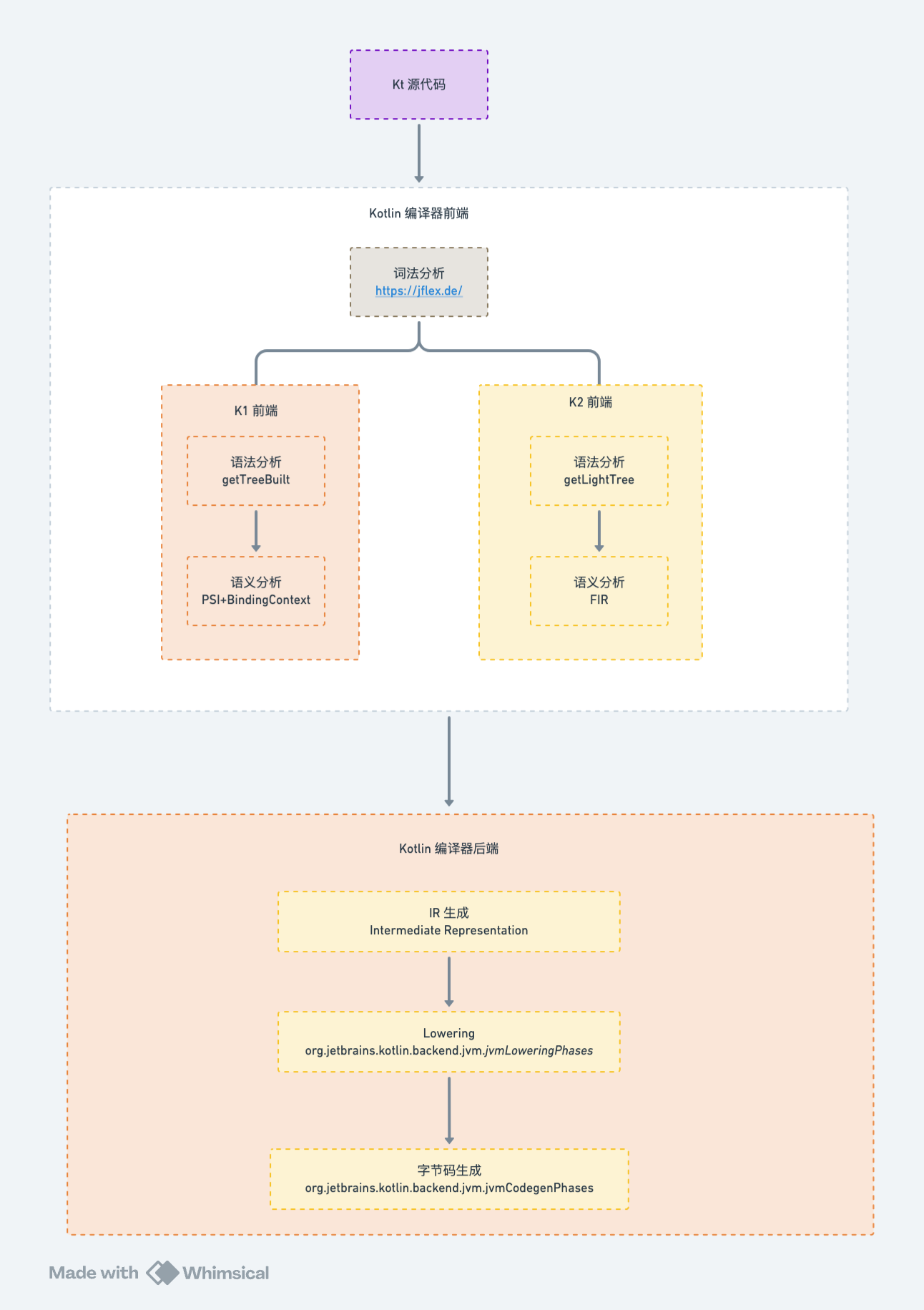
Kotlin 的编译器其实也是由这些部分组成的,下面就按这几个部分来介绍一下 Kotlin 的编译流程。本文基于 Kotlin 2.1 源码分析。
Kotlin 编译器如何调试?
要想了解 Kotlin 的编译过程,最好的方式就是通过 IDEA debug 来了解这一过程。为了实现这点,首先我们需要找到 kotlin 编译的入口类,然后通过修改入口类传入我们自定义的 kt 源代码。
我们可以通过分析 kotlinc 的编译过程来找到入口类,当我们通过 kotlinc 编译 kotlin 源代码的时候发生了什么呢?我们可以首先看看 kotlinc 脚本的源码:
java_version="$(findJavaVersion)"
if [[ $java_version -ge 9 ]]; then
# Workaround the illegal reflective access warning from ReflectionUtil to ResourceBundle.setParent, see IDEA-248785.
java_args=("${java_args[@]}" "--add-opens" "java.base/java.util=ALL-UNNAMED")
fi
if [ -n "$KOTLIN_RUNNER" ]; then
java_args=("${java_args[@]}" "-Dkotlin.home=${KOTLIN_HOME}")
kotlin_app=("${KOTLIN_HOME}/lib/kotlin-runner.jar" "org.jetbrains.kotlin.runner.Main")
else
[ -n "$KOTLIN_COMPILER" ] || KOTLIN_COMPILER=org.jetbrains.kotlin.cli.jvm.K2JVMCompiler
if [[ $java_version < 13 ]]; then
java_args=("${java_args[@]}" "-noverify")
fi
declare additional_classpath=""
if [ -n "$KOTLIN_TOOL" ]; then
additional_classpath=":${KOTLIN_HOME}/lib/${KOTLIN_TOOL}"
fi
kotlin_app=("${KOTLIN_HOME}/lib/kotlin-preloader.jar" "org.jetbrains.kotlin.preloading.Preloader" "-cp" "${KOTLIN_HOME}/lib/kotlin-compiler.jar${additional_classpath}" $KOTLIN_COMPILER)
fi
"${JAVACMD:=java}" $JAVA_OPTS "${java_args[@]}" -cp "${kotlin_app[@]}" "${kotlin_args[@]}"
通过查看 kotlinc 源码可知,org.jetbrains.kotlin.preloading.Preloader 类是编译器的预加载器,它会加载编译器的主类 org.jetbrains.kotlin.cli.jvm.K2JVMCompiler。因此我们修改Preloader类,运行它的main方法,即可启动与调试编译器,示例如下所示:
String[] testArgs = {"-cp", "./dist/kotlinc/lib/kotlin-compiler.jar", "org.jetbrains.kotlin.cli.jvm.K2JVMCompiler",
"./compilerTestData/Test.kt", "-include-runtime",
"-d", "./compilerTestData/Test.jar",
//"-language-version","1.9" 当需要使用 K1 编译器时添加此参数。
};
run(testArgs);
通过以上步骤,就可以实现 IDE 调试 kotlin 的编译过程。
词法分析
这一步的输入是源代码,输出是一系列的记号(tokens),每个记号代表源代码中的词法单元,如关键字、标识符、操作符、分隔符,注释等。
转换的过程是通过扫描源代码,根据 Kotlin 的词法规则,将源代码分割成一个个的词法单元。这个过程是由词法分析器(Lexical Analyzer)完成的。
由于词法分析器已经是一个比较成熟的技术,因此我们可以直接使用现成的工具来生成词法分析器。
Kotlin 就是使用了 JFlex 来生成词法分析器,通过编写 JFlex 规范文件 /Kotlin.flex,然后使用 JFlex 工具即可生成词法分析器。
JFlex 是一个词法分析器生成器(也称为扫描器生成器),使用 Java 编写。
一个词法分析器生成器的输入是一个包含一组正则表达式及其相应动作的规范。它生成一个程序(词法分析器),该程序读取输入,将输入与规范文件中的正则表达式进行匹配,如果某个正则表达式匹配成功,则执行相应的动作。词法分析器通常是编译器的第一个前端步骤,用于匹配关键字、注释、操作符等,并为解析器生成输入的标记流。
JFlex 的词法分析器基于确定性有限自动机(DFA)。它们运行快速,没有昂贵的回溯操作。
JFlex 设计用于与 Scott Hudson 的 LALR 解析器生成器 CUP 共同使用,以及用于 Bob Jamison 修改自 Berkeley Yacc 的 Java 版本 BYacc/J。它也可以与其他解析器生成器(如 ANTLR)一起使用,或者作为独立工具使用。
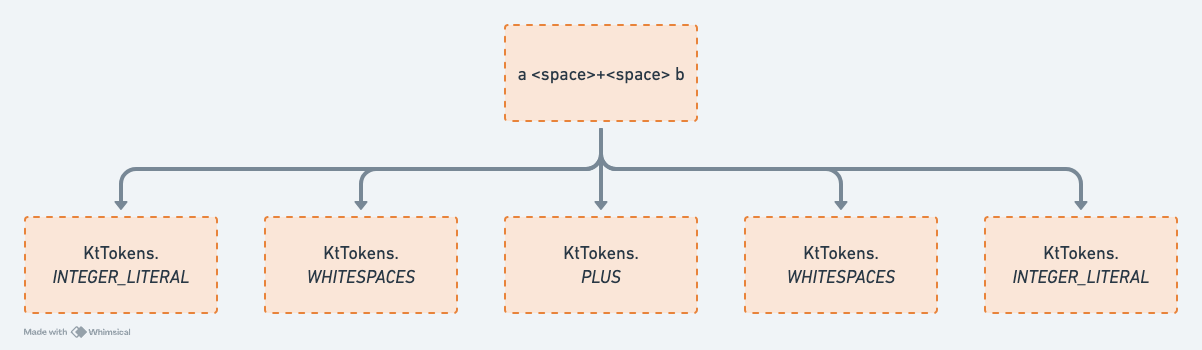
语法分析
这一步的输入是 Tokens, 根据 Kotlin 的语法规则处理 Tokens,输出 AST(abstrace syntax tree)。
Kotlin 的语法规则可见:https://kotlinlang.org/docs/reference/grammar.html。以下是 class 的定义,当遍历 tokens 列表时,如果碰到了 class 或者 interface 关键字,后续的 tokens 则按类或者 interface 来解析,其他语法规则也是如此,如果碰到不符合语法规则的语句则会报错。
classDeclaration (used by declaration)
: modifiers? ('class' | ('fun'? 'interface'))
simpleIdentifier typeParameters?
primaryConstructor?
(':' delegationSpecifiers)?
typeConstraints?
(classBody | enumClassBody)?
;
K1 与 K2 在语法分析阶段的输出略有不同, K2 在语法分析阶段会返回一个更加轻量级的语法树,构建速度更快,但后续无法创建 PSI。
/**
* 返回解析的结果。在调用此方法之前,所有的标记必须已经完成或被丢弃。
*
* @return 构建的 AST 树
*/
@NotNull
ASTNode getTreeBuilt();
/**
* 与 getTreeBuilt() 相同,但返回一个轻量级的树,构建速度更快,产生的垃圾更少,但无法创建一个 PSI(程序结构接口)。
*
* @return 轻量级的语法树
*/
@NotNull
FlyweightCapableTreeStructure<LighterASTNode> getLightTree();
K1 版本语法分析
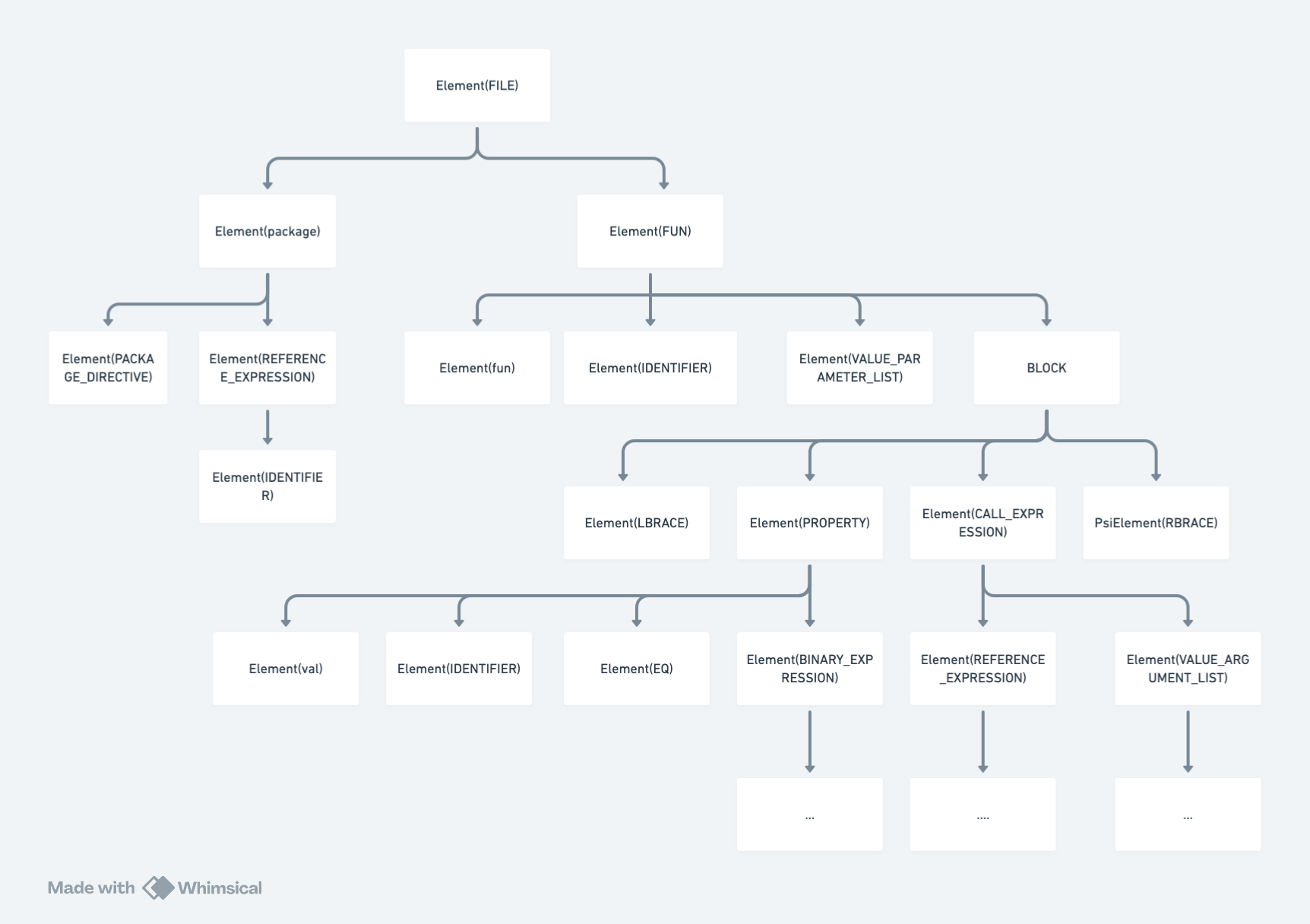
package compilerTestData
fun sample(a: Int, b: Int) {
val c = a + b
println("result:" + c)
}
以上代码,语法分析后创建的 ASTNode 语法树如下所示
K2 版本语法分析
相比之下,K2 编译器在语法分析阶段会通过getLightTree创建一个 LightTree,LighterASTNode 比 ASTNode 更加轻量化,接口中只有几个方法,后续无法创建 PSI
public interface LighterASTNode {
LighterASTNode[] EMPTY_ARRAY = new LighterASTNode[0];
IElementType getTokenType();
int getStartOffset();
int getEndOffset();
default int getTextLength() {
return getEndOffset() - getStartOffset();
}
}
语义分析
这一步的输入是语法树,输出则是带有语义信息的语法树。K1 与 K2 阶段略有不同。
K1 版本语义分析
PSI
在 K1 编译器中,语义分析阶段需要首先将 ASTNode 树再通过createElement转化为 PsiElemet 树。
override fun createElement(astNode: ASTNode): PsiElement {
val elementType = astNode.elementType
return when (elementType) {
is KtStubElementType<*, *> -> elementType.createPsiFromAst(astNode)
KtNodeTypes.TYPE_CODE_FRAGMENT, KtNodeTypes.EXPRESSION_CODE_FRAGMENT, KtNodeTypes.BLOCK_CODE_FRAGMENT -> ASTWrapperPsiElement(
astNode
)
is KDocElementType -> elementType.createPsi(astNode)
KDocTokens.MARKDOWN_LINK -> KDocLink(astNode)
else -> (elementType as KtNodeType).createPsi(astNode)
}
}
在 IntelliJ Platform 中,解析文件是一个两步走的过程:
第一步,构建抽象语法树(AST),定义程序的结构。AST 节点由 IDE 内部创建,由 ASTNode 类的实例表示。每个 AST 节点都有一个关联的元素类型(IElementType 实例),这些元素类型由语言插件定义。
第二步,在 AST 之上构建程序结构接口(PSI)树,添加语义和用于操作特定语言结构的方法。PSI 树的节点由实现 PsiElement 接口的类表示,这些类由语言插件在 ParserDefinition.createElement() 方法中创建。
看起来 AST 和 PSI 都是代表语法树,那么为什么要再多一层呢?
实际上 PSI 在 IDEA 语法分析,代码补全等场景中大量使用,同时 IDEA 也支持自定义语言的支持,详情可见:Custom Language Support
Kotlin 在开发之初,应该是为了复用 IDEA 生态而使用了 PSI。但是 IDE 场景与编译器场景其实有些不同,IDE 会有频繁更新代码,快速导航等应用场景,因此 PSI 需要支持缓存,懒加载,增量更新,导航等功能,而这些功能自然有一定成本,而在编译过程中实际并不需要,自然也会影响编译性能。
BindingContext
在 K1 编译器中,分析过程中收集的语义信息会存储到 BindingContext 中,具体包括以下内容:
- 声明到描述符的映射
- 表达式类型信息
- 诊断信息
- 解析的导入
- 作用域信息
在 BindingContext 内部使用 SlicedMap 来存储语义信息
public interface BindingContext {
// ...
WritableSlice<KtReferenceExpression, DeclarationDescriptor> REFERENCE_TARGET = new BasicWritableSlice<>(DO_NOTHING);
// ...
@Nullable
<K, V> V get(ReadOnlySlice<K, V> slice, K key);
}
public interface SlicedMap {
SlicedMap DO_NOTHING = new SlicedMap() {
@Override
public <K, V> V get(ReadOnlySlice<K, V> slice, K key) {
return slice.computeValue(this, key, null, true);
}
@Override
public <K, V> Collection<K> getKeys(WritableSlice<K, V> slice) {
return Collections.emptySet();
}
@Override
public void forEach(@NotNull Function3<WritableSlice, Object, Object, Void> f) {
}
};
<K, V> V get(ReadOnlySlice<K, V> slice, K key);
}
可以看出,SlicedMap 中使用切片来存储数据,在获取语义信息时,我们通过需要传入切片类型与 PsiElement,如下所示
override fun visitReferenceExpression(expression: KtReferenceExpression) {
val descriptor = bindingContext[BindingContext.REFERENCE_TARGET, expression])
// ...
}
相比直接使用 Map,使用 SlicedMap 有以下几个优势:
- 类型安全:SlicedMap 通过使用切片来定义键和值的类型,从而实现类型安全的存储和检索。这减少了类型错误的风险。
- 关注点分离:通过使用切片,SlicedMap 将不同类型的数据分离到不同的切片中,使代码更加模块化,易于管理。
- 性能优化:SliceMap 内部进行了一系列优化适配编译器场景,在编译器场景下可以带来更好的读写性能。
K2 版本语义分析
K2 编译器中,语义分析分为两步
- 将
lightTree转化为 Fir 树 - 进行代码分析和检查,并将语义信息写入到 Fir 树中
fun buildResolveAndCheckFirViaLightTree(
session: FirSession,
ktFiles: Collection<KtSourceFile>,
diagnosticsReporter: BaseDiagnosticsCollector,
countFilesAndLines: KFunction2<Int, Int, Unit>?
): ModuleCompilerAnalyzedOutput {
val firFiles = session.buildFirViaLightTree(ktFiles, diagnosticsReporter, countFilesAndLines)
return resolveAndCheckFir(session, firFiles, diagnosticsReporter)
}
与 K1 版本相比,K2 版本生成的是带有语义信息的语法树,通过 Fir 树中的symbol就可以获取语义信息,而不需要从庞大的BindingContext中去查询。
sealed class FirDeclaration : FirElementWithResolveState(), FirAnnotationContainer {
abstract override val source: KtSourceElement?
abstract override val annotations: List<FirAnnotation>
abstract val symbol: FirBasedSymbol<FirDeclaration>
abstract override val moduleData: FirModuleData
abstract val origin: FirDeclarationOrigin
abstract val attributes: FirDeclarationAttributes
override fun <R, D> accept(visitor: FirVisitor<R, D>, data: D): R =
visitor.visitDeclaration(this, data)
@Suppress("UNCHECKED_CAST")
override fun <E : FirElement, D> transform(transformer: FirTransformer<D>, data: D): E =
transformer.transformDeclaration(this, data) as E
abstract override fun replaceAnnotations(newAnnotations: List<FirAnnotation>)
abstract override fun <D> transformAnnotations(transformer: FirTransformer<D>, data: D): FirDeclaration
}
IR 生成
这一步的输入是带有语义信息的语法树,输出则是 IR 树。IR(Intermediate Representation,中间表示)是一个介于源代码和目标代码码之间的抽象层,通过引入 IR,Kotlin 可以更加高效的支持多平台。
abstract class IrFile : IrPackageFragment(), IrMutableAnnotationContainer, IrMetadataSourceOwner {
abstract override val symbol: IrFileSymbol
abstract var module: IrModuleFragment
abstract var fileEntry: IrFileEntry
override fun <R, D> accept(visitor: IrElementVisitor<R, D>, data: D): R =
visitor.visitFile(this, data)
override fun <D> transform(transformer: IrElementTransformer<D>, data: D): IrFile =
accept(transformer, data) as IrFile
override fun <D> acceptChildren(visitor: IrElementVisitor<Unit, D>, data: D) {
declarations.forEach { it.accept(visitor, data) }
}
override fun <D> transformChildren(transformer: IrElementTransformer<D>, data: D) {
declarations.transformInPlace(transformer, data)
}
}
IR 树的声明如上所示,IR 树可以通过访问者模式来遍历子节点,也可以通过dump方法直接打印出来,dump后结果如下所示:
MODULE_FRAGMENT name:<main>
FILE fqName:compilerTestData fileName:/Users/jiangjunxiang/AndroidProject/leo/kotlin/compilerTestData/Test.kt
FUN name:sample visibility:public modality:FINAL <> (a:kotlin.Int, b:kotlin.Int) returnType:kotlin.Unit
VALUE_PARAMETER name:a index:0 type:kotlin.Int
VALUE_PARAMETER name:b index:1 type:kotlin.Int
BLOCK_BODY
VAR name:c type:kotlin.Int [val]
CALL 'public final fun plus (other: kotlin.Int): kotlin.Int [operator] declared in kotlin.Int' type=kotlin.Int origin=PLUS
$this: GET_VAR 'a: kotlin.Int declared in compilerTestData.sample' type=kotlin.Int origin=null
other: GET_VAR 'b: kotlin.Int declared in compilerTestData.sample' type=kotlin.Int origin=null
CALL 'public final fun println (message: kotlin.Any?): kotlin.Unit [inline] declared in kotlin.io.ConsoleKt' type=kotlin.Unit origin=null
message: CALL 'public final fun plus (other: kotlin.Any?): kotlin.String [operator] declared in kotlin.String' type=kotlin.String origin=PLUS
$this: CONST String type=kotlin.String value="result:"
other: GET_VAR 'val c: kotlin.Int [val] declared in compilerTestData.sample' type=kotlin.Int origin=null
lowering
lowering 是指将高级的 Kotlin 代码转换成更加底层的、容易被后续编译阶段或目标平台(如 JVM 字节码、JavaScript、原生代码等)理解并处理的代码的过程。这个过程通常包括将更抽象、高级的语言特性分解成更基础的元素。具体来说,lowering 会涉及到以下几点:
- 语法糖的展开(Desugaring): 将语法糖形式(syntactic sugar)的代码转换成更基础的代码。例如,Kotlin 中的 lambda 表达式、扩展函数、高阶函数等高级特性,在 lowering 过程中会被转换成相应的普通函数或方法调用。
- 内联函数(Inlining): 内联函数在 lowering 阶段会被替换成函数体自身的代码,以减少函数调用的开销。
- 协程转换(Coroutine Transformation): Kotlin 的挂起函数(suspend function)和协程(coroutines)特性在 lowering 阶段会被转换成状态机形式,以便在目标平台上高效运行。
- 类和对象相关转换: 将对象表达式、匿名对象、伴生对象等高级特性转换成可以被目标平台理解的普通类结构。
- 其他变换: 将局部返回、智能类型转换等 Kotlin 特性转换成更基础的构造。
比如代码中字符串的+操作,在lowering之后就转化为了append方法
MODULE_FRAGMENT name:<main>
FILE fqName:compilerTestData fileName:/Users/jiangjunxiang/AndroidProject/leo/kotlin/compilerTestData/Test.kt
CLASS FILE_CLASS CLASS name:TestKt modality:FINAL visibility:public superTypes:[kotlin.Any]
$this: VALUE_PARAMETER INSTANCE_RECEIVER name:<this> type:compilerTestData.TestKt
FUN name:sample visibility:public modality:FINAL <> (a:kotlin.Int, b:kotlin.Int) returnType:kotlin.Unit
VALUE_PARAMETER name:a index:0 type:kotlin.Int
VALUE_PARAMETER name:b index:1 type:kotlin.Int
BLOCK_BODY
VAR name:c type:kotlin.Int [val]
CALL 'public final fun plus (other: kotlin.Int): kotlin.Int [operator] declared in kotlin.Int' type=kotlin.Int origin=PLUS
$this: GET_VAR 'a: kotlin.Int declared in compilerTestData.TestKt.sample' type=kotlin.Int origin=null
other: GET_VAR 'b: kotlin.Int declared in compilerTestData.TestKt.sample' type=kotlin.Int origin=null
CALL 'public final fun println (message: kotlin.Any?): kotlin.Unit [inline] declared in kotlin.io.ConsoleKt' type=kotlin.Unit origin=null
message: CALL 'public final fun toString (): kotlin.String declared in java.lang.StringBuilder' type=kotlin.String origin=null
$this: CALL 'public final fun append (value: kotlin.Int): java.lang.StringBuilder declared in java.lang.StringBuilder' type=java.lang.StringBuilder origin=null
$this: CALL 'public final fun append (value: kotlin.String?): java.lang.StringBuilder declared in java.lang.StringBuilder' type=java.lang.StringBuilder origin=null
$this: CONSTRUCTOR_CALL 'public constructor <init> () declared in java.lang.StringBuilder' type=java.lang.StringBuilder origin=null
value: CONST String type=kotlin.String value="result:"
value: GET_VAR 'val c: kotlin.Int [val] declared in compilerTestData.TestKt.sample' type=kotlin.Int origin=null
目标代码生成
最后一步当然就是生成目标代码了,具体到 Kotlin/JVM 也就是生成 Java 字节码。在这一步,主要通过遍历 IrFile 及其子节点,通过 ASM 生成字节码,最后将生成的字节码写入 .class 文件也就完成了,具体包括以下几步。
- 字节码生成: 通过 ClassCodegen 执行字节码生成逻辑,包括类生成,方法生成,字节码指令生成等。
- 字节码优化:生成的字节码通过 OptimizationMethodVisitor 和其他 ASM 工具进行进一步优化,确保字节码质量和执行效率。
- 类文件生成: 将字节码写入 .class 文件,这是 JVM 能够直接加载和执行的格式。
为什么 K2 比 K1 快?
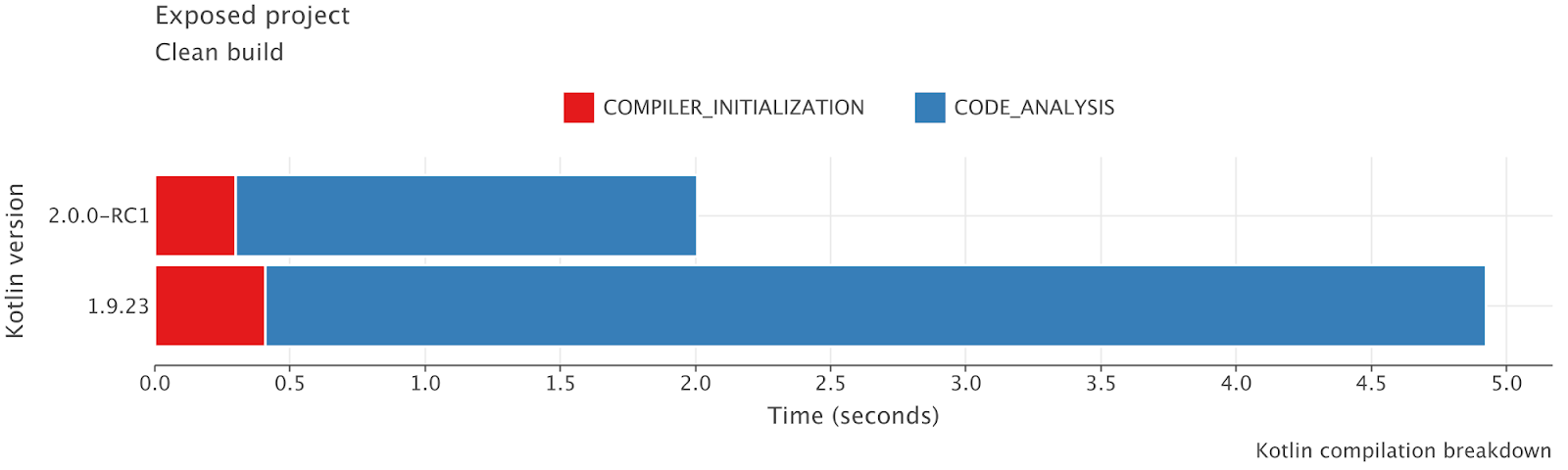
根据 jetbrains 的 benchmark,K2 的性能比起 K1 在分析阶段有着显著的提升,那么是为什么呢?
从我们上面的分析来看,一部分原因在于 K1 编译器为了复用了 IDEA 生态使用了 PSI ,但是 IDE 会有频繁更新代码,快速导航等应用场景,这些在编译场景并不需要的功能会带来一定的性能开销,自然会对编译速度产生一定的影响。
此外根据 Dmitriy Novozhilov [JetBrains] 在 Slack 中的解释, K1 编译器在代码局部性和内存局部性上也存在一些问题。
FE 1.0 性能的主要问题与非常差的代码局部性和内存局部性有关。所有描述符都是延迟加载的,因此编译器总是在不同的代码部分之间跳转,这破坏了许多即时编译(JIT)优化。 此外,所有关于解析的信息都存储在一个巨大的映射嵌套映射(绑定上下文)中,所以 CPU 不能很好地缓存对象。
总结