编译器插件
本文为《深入实践 kotlin 元编程》读书笔记,想要深入了解 kotlin 元编程的同学可以阅读原书。
编译器插件概述
编译器插件是编译器在一定范围内为开发者提供的定制编译过程的能力。
什么是编译器插件
编译器的执行流程是一个相对标准化的过程。编译过程当中包含很多环节,环节与环节之间通过输入输出连接起来,只要编译器提供了相应的 API,我们就可以通过编写插件的形式从外部 介入这些特定的编译环节。
编译器插件能做什么
Kotlin 编译器插件的具体能力范围取决于 API 的开放情况。我们可以通过阅读源码,搞清楚编译器插件的扩展点(Extension Point)的作用,通过分析这些扩展点,我们大致可以了解到编译器插件的能力范围:
- 语法检查,例如对某些合法的语法添加更加严格的检查。
- 生成新的包、类、函数、属性等,Kotlin Android Extensions 和 Parcelize 插件当中大量使用到了代码生成的能力。
- 修改代码的编译产物。
需要注意的是,目前来看,Kotlin 的语法树无法在编译器插件当中被直接修改,因此不要寄希望于通过开发编译器插件来为 Kotlin 添加新语法。
编译器插件项目的基本结构
编译器插件除了自身的逻辑以外,还需要与编译工具链(Toolchain)、集成开发环境(IDE)配合,因此通常来说一个完整的编译器插件项目会包含
- 一个编译器插件模块
- 编译工具链插件模块(gradle, maven)
- 集成开发环境插件模块
编译器插件模块
Kotlin 的编译器入口是 kotlinc,kotlinc 是一个 JVM 程序。编译器插件需要加载到编译器当中运行,因此也是一个 JVM 程序,它的产物通常就是一个 jar 文件。
编译器插件模块需要依赖 Kotlin 编译器,以调用编译器插件的 API。Kotlin 团队已经将 Kotlin 编译器作为一个独立的 jar 文件发布到了 Maven 仓库,我们只需要添加依赖即可
在编译器插件模块主要完成两个任务:
- 解析命令行参数
- 注册扩展点
编译工具链插件模块
通常情况下,我们会使用 Gradle 或者 Maven 来管理 Kotlin 项目。为了方便将编译器插件集成到整体的编译流程当中,每一个 Kotlin 编译器插件项目都需要同时提供相应的 Gradle 和 Maven 插件模块。
集成开发环境插件模块
开发环境插件模块不是必须的。通常只有在编译器插件的处理结果导致代码提示的行为发生了变化之后才需要提供配套的开发环境插件,例如生成了新的函数,修改了类的修饰符等等。
插件的发布
依赖包名重定向
Kotlin 团队在发布 Kotlin 编译器时,除了 kotlin-compiler 这个构件以外,还发布了一个 kotlin-compiler-embeddable 的构件。这两个构件都是 Kotlin 的编译器, 二者有什么区别呢?
原来,为了确保编译器的完整性和独立性,Kotlin 团队将 Kotlin 编译器依赖的一些第三方依赖也一并打包到了编译器的构件当中。
这样做确实可以解决编译器完整性和独立性的问题,不过也会引入新的问题。例如,如果一个程序同时引入了 Kotlin 编译器和 Proto Buffer,那么编译时就会因 Kotlin 编译器当 中同样存在一份 Proto Buffer 的类而导致冲突。
为了解决这个问题,Kotlin 编译器在构建时会将这些第三方依赖的包名做重定向,例如:com.intellij 就被重定向成了 org.jetbrains.kotlin.com.intellij。
在插件当中应用包名重定向
为了在插件当中应用包名重定向,最常见的做法就是新建一个空模块,依赖之前写好的编译器插件,并通过修改编译逻辑来实现包名的重定向。
直接依赖 embeddable 的编译器
既然 kotlin-compiler-embeddable 当中已经对这些第三方的类做了重定向,我们直接依赖它并基于重定向之后的类做开发不就可以了吗?
这当然是可以的,不过前提是我们的编译器插件项目不需要同时提供 IntelliJ 插件。
由于 IntelliJ 插件的运行环境是确定的,不会存在依赖冲突的问题,因此运行在 IntelliJ 环境当中的 Kotlin 编译器是没有经过包名重定向的。换句话,我们为了让 IntelliJ 插件能够共享编译器插件当中的逻辑,就必须让编译器插件依赖 kotlin-compiler,而不是对应的 embeddable 版本。
符号处理器的实现原理
Java 存根的生成
KAPT 本质上仍然是 Java 编译器提供的符号处理机制。在 KAPT 执行时,Kotlin 编译器会将 Kotlin 源码转译成 Java 存根,这其中就包含了符号处理过程当中必须的 Java 符号信息。
Java 存根的转译主要包含 Kotlin 代码编译生成 JVM 字节码、JVM 字节码转换成 Java 语法树、打印 Java 语法树几个关键环节。
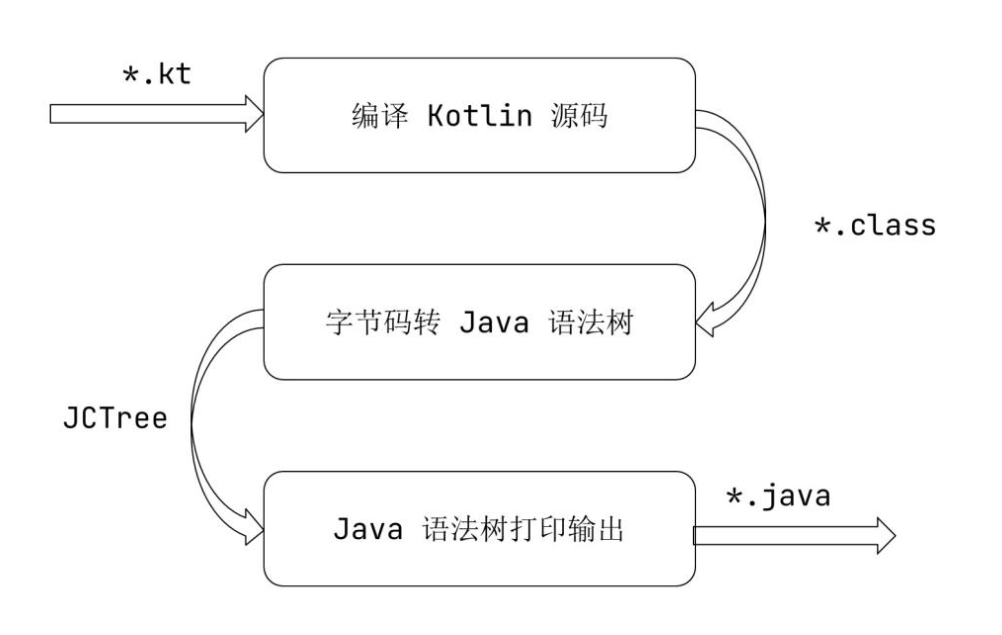
Kotlin 编译器编译生成 JVM 字节码这一步比较容易理解,执行的就是完整的 Kotlin 代码的编译流程。如果 Kotlin 源码当中引用了待生成的类型,这些类型在编译时会被替换成 NonExistentClass。
Kotlin 源码经过编译之后得到 JVM 字节码,再转换成 Java 语法树。这一步的相关实现主要在 ClassFileToSourceStubConverter 文件当中,完成了顶级类从 ASM 的 ClassNode 结构到 Java 语法树的 JCCompilationUnit 结构的转换。此外,这一步还会根据实际需要生成 NonExistentClass。
最后一步就比较简单了,就是单纯地将 JCCompilationUnit 以文本的形式输出到文件当中,得到最终的 Java 存根。
Java 编译器的调用
生成 Java 存根之后,KAPT 会将原本的 Java 源码和新生成的 Java 存根一起作为 Java 编译器的输入,以执行符号处理的逻辑。
增量编译的支持
Java 存根的增量生成
当只有部分 Kotlin 源码发生修改时,编译时可以利用 Kotlin 编译器的增量特性将发生修改的源文件进行编译,并生成 JVM 字节码。这一步编译的结果默认保存于 build/tmp/kapt3/incrementalData 目录当中。后续的处理流程则以类为单位一一进行处理。由此可见,Java 存根的增量生成只依赖于第一步的 Kotlin 源码的增量编译。
处理器的增量执行
Java 编译器本身没有对增量编译直接提供支持,因而也不会对符号处理提供增量支持。
符号处理器的增量编译直接取决于生成的目标文件和源文件的依赖关系,即在创建目标文件时传入的 originatingElements。
而 Java 编译器的默认实现 JavacFiler 却没有用到这个参数。Gradle 为了支持 Java 注解处理器的增量编译,提供了自己的 IncrementalFiler 实现,KAPT 为了兼容 Gradle 的增量编译机制也提供了自己的 IncrementalFiler 实现。
多轮次符号处理
在多轮次符号处理的实现上, KAPT 和 KSP 差异较大。
KAPT 调用了 Java 编译器,多轮次处理的逻辑由 Java 编译器负责,而 KAPT 的 Kotlin 编译器插件对此完全不需要关心。这也能很好的解释为什么 KAPT 的处理器无法在后续轮次的符号处理中处理新生成的 Kotlin 源文件了,因为整个符号处理的过程由 Java 编译器全权负责,KAPT 没有合适的时机为新生成的 Kotlin 源文件生成 Java 存根。
而 KSP 作为一款纯粹的 Kotlin 编译器插件,可以充分利用 Kotlin 编译器的能力来实现多轮次的符号处理。
KSP 是支持在多轮次符号处理中对新生成的 Java 和 Kotlin 源文件进行处理的。这也是 KSP 相比 KAPT 更有优势的一个细节。