元数据简介
本文为《深入实践 kotlin 元编程》读书笔记,想要深入了解 kotlin 元编程的同学可以阅读原书。
基本概念
元数据(Metadata)是指描述其他数据的信息的数据,不包含被描述的数据的内容。例如 一个字符串一共有 10 个字符,这里的 10 个字符的长度就是这个字符串的元数据。
具体到我们讨论的 Kotlin 元编程的范畴,元数据可以理解为描述目标程序本身的信息,例如代码的行数、语法树,甚至编译后的产物等等。按照元数据的产生途径,我们可以简单将其分为两种类型,即语法结构和编译产物。
注解
注解(Annotation)是一种可以在源码当中添加元数据的语法。注解在 Kotlin 元编程 中扮演了非常重要的角色。
注解的概念
注解和注释是两个措辞和功能都比较接近的概念,不同之处在于注解是一种有着严格的语法定义和使用约束的结构化信息,是专门为元编程设计的语法结构。
根据注解在程序不同阶段的可见性,我们可以将其分为三类:
- 源代码可见的注解
- 二进制可见的注解
- 运行时可见的注解
源代码可见的注解
源代码可见的注解在定义时,需要将 @Retention 的参数设置为 AnnotationRetention.SOURCE。此类注解不会存在于编译产物当中,可以用来做代码提示, 编译配置,也可以在编译时使用 KAPT、KSP 或者编译器插件实现代码生成、代码检查等功能。
二进制可见的注解
二进制可见的注解在定义时,需要将 @Retention 的值设置为 AnnotationRetention.BINARY。此类注解会存在于编译产物当中,但对运行时不可见,除适用于源代码可见的注解的所有使用场景以外,也适用于对编译产物进行处理的场景。
运行时可见的注解
运行时可见的注解在定义时,需要将 @Retention 的值设置为 AnnotationRetention.RUNTIME。此类注解会存在于编译产物当中,并对运行时可见,除适用于二进制可见的注解的全部使用场景以外,也可在运行时通过反射访问。
Kotlin 的 Metadata
Kotlin 有自己专属的 Metadata 设计,主要用于为编译产物提供完善的 Kotlin 语法信息。
Kotlin JVM 当中的 @Metadata 注解
Kotlin 提供了很多 Java 不支持的特性,这些特性也很难直接使用 JVM 字节码进行等 价的描述。为了确保发布的二进制产物当中包含完整的 Kotlin 的语法信息,Kotlin 编译器 为每一个类生成一个 @Metadata 注解,同时也会为模块内所有的顶级声明生成一个模块专属的 metadata 文件,这些文件通常以 kotlin_module 为后缀。
@Metadata 注解的定义
public annotation class Metadata(
// metadata 的类型,共 5 种 @get:JvmName("k")
val kind: Int = 1,
// metadata 的版本 @get:JvmName("mv")
val metadataVersion: IntArray = [],
// metadata 的自定义格式数据,格式取决于 kind @get:JvmName("d1")
val data1: Array<String> = [],
// data1 的补充,内容是字符串常量,可以直接存入常量池方便复用 @get:JvmName("d2")
val data2: Array<String> = [],
... // 省略部分字段 )
Kotlin 反射与 @Metadata
Kotlin 反射之所以可以在运行时获取到 Kotlin 特有的各种语法信息,也正是得益于对 @Metadata 注解所包含的信息的读取。
由于需要处理 @Metadata 注解的反序列化,Kotlin 反射相比 Java 反射在初始化对应 类型时会稍慢一些,后续的使用当中二者的性能则差异不大。
Kotlin JVM 库当中的 metadata
在 Kotlin JVM 模块中,后缀为 kotlin_module 的文件存储了模块内 JVM 字节码不 支持的顶级声明的信息,包括函数、属性、类型别名等。如果我们在打包发布自己的模块时没有携带<模块名>.kotlin_module 文件,就会导致这些顶级声明无法正常被其他调用者使用。
Kotlin 的语法树
Kotlin 源代码在编译时,经过词法分析、语法分析之后,会生成相应的语法树。
第一代 Kotlin 编译器基于 IntelliJ 平台的 PSI 实现了自己的语法树;第二代 Kotlin 编译器(即 K2 Compiler,下称 K2 编译器)则设计实现了一套全新的语法结构, 称为 FIR(Front-end IR,前端中间代码表示)。
FE1.0 的语法树之所以选择基于 IntelliJ 平台的 PSI 实现,好处自然是可以尽可能地复用 IntelliJ 平台已有的技术积累,在早期可以快速实现需求。但长久来看,这也会使得 Kotlin 编译器严重依赖于 IntelliJ 平台自身的迭代而难以实现针对性的优化。为了解决这 个问题,Kotlin 团队从 1.6 开始就在持续研发一款新的前端编译器,也就是 K2 编译器的 FIR 前端。
在 FE1.0 中,前端编译器的输出包含 PSI 树和 BindingContext 两部分,其中 BindingContext 实际上就是语义分析结果的映射表,包含了 PSI 节点到对应的语义信息的 映射关系。相比之下,FIR 的节点当中包含了完整的语义分析结果,因此在获取语义分析时无须反复查表,无论从代码的可读性上还是从执行效率上都有很大的提升。
连接前后端编译器的 IR
Kotlin IR(Intermediate Representation,中间表示)最早在 Kotlin Native 的编译器当中设计实现。IR 对于 Kotlin 编译器的实现非常重要,这可以使得 Kotlin 的前 后端编译器分离,各自优化和迭代。同时,不同目标平台的后端编译器均可以使用 Kotlin IR 作为统一的输入,这也为后续扩展新平台提供了非常便利的条件。
自 Kotlin 1.5 以来,Kotlin JVM 和 JS 的后端编译器也已经陆续迁移至 IR 编译 器,WASM 的后端编译器也基于 Kotlin IR 做了重新实现。
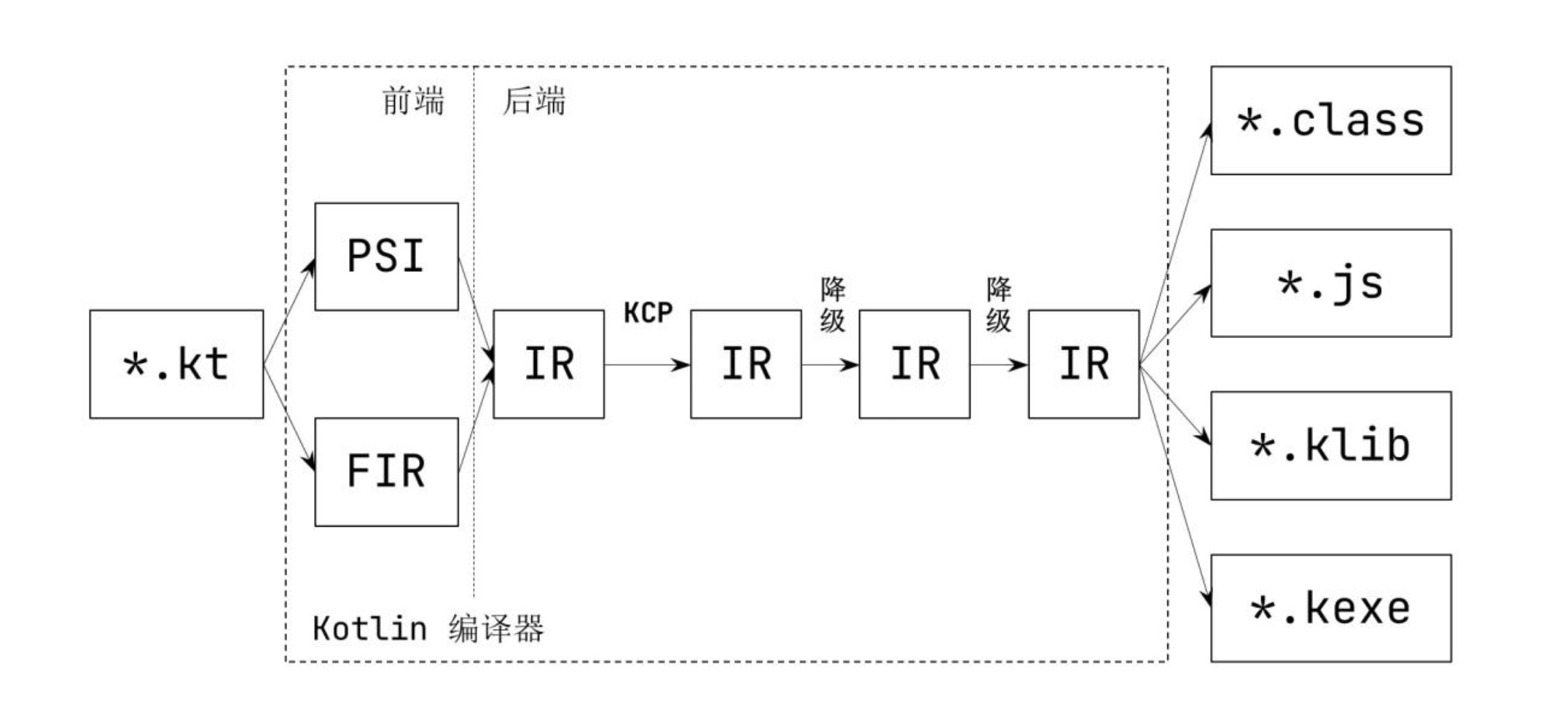
IR 最初由 PSI 或者 FIR 转换而来,接着由编译器插件的处理,之后再经过一系列降级(Lowering),最终交由目标程序生成器生成最终的目标程序。降级操作非常多,每一个降级阶段都只是一个独立且细节的优化步骤。
Java 和 Kotlin 的符号树
APT 是 Java 当中最重要的元编程技术之一,它本质上是 Java 编译器提供的元编程 API。
Kotlin 从 1.0 开始就逐步实现了对 APT 的支持,即 KAPT。KAPT 实际上是一个编译 器插件,它先将 Kotlin 代码转成 Java 存根(Java Stubs),作为 Java 编译器的输入进 而支持 APT。
因此,使用 KAPT 对 Kotlin 源码进行处理时,我们能够访问到的实际上就是 Java 符号树,即使源代码是使用 Kotlin 编写的。
随着 Kotlin 的日益普及,KAPT 这个“曲线救国”方案的弊端也逐渐显现。一方面 Java 符号很难反应真实的 Kotlin 源代码当中的符号信息,因而我们不得不经常借助 @Metadata 注解来还原真实的 Kotlin 符号;另一方面,KAPT 总是需要先生成 Java 存根,这对于有一定规模的项目来说简直就是灾难。
为了解决这个问题,Google 开源了 KSP(Kotlin Symbol Processing,Kotlin 符 号处理器),基于 Kotlin 编译器插件将 Kotlin 的语法树抽象成符号树,完美地解决了 KAPT 存在的问题。
KSP 除了支持 Kotlin 之外,也会把 Java 符号抽象成 Kotlin 符号,因此我们完全 可以使用 KSP 来替代 KAPT。
Kotlin 的编译产物
JVM
严格意义上来讲,对于 Kotlin 编译器的编译产物的处理不属于典型的 Kotlin 元编程 的范畴。不过,由于 Kotlin 广泛应用于 JVM 环境当中,因此 JVM 字节码分析和编辑技术 也是 Kotlin 开发者经常需要面对的元编程场景。
通过编辑 JVM 字节码可以应对的需求场景有很多。例如:
- 去除 @Metadata 注解。Kotlin 标准库和反射库在编译时就会使用 ASM 来去除自身无用的 @Metadata 注解,以减少产物体积。
- 拦截或者替换方法调用。我们经常希望应用内部对某些特定 API 的访问是可控的,对于第三方 SDK,我们就可以使用字节码编辑技术来实现“偷梁换柱”。