编译时的符号处理
本文为《深入实践 kotlin 元编程》读书笔记,想要深入了解 kotlin 元编程的同学可以阅读原书。
除了直接生成源代码,我们有时还会面临一种更加复杂的场景,即如何基于人工编写的源代码来生成代码,甚至还可以让二者相互调用。
为了应对这种需求场景,Java 和 Kotlin 编译器均提供了相应的扩展支持,允许我们编写一些特定的程序来访问源代码当中特定的语法结构,并完成代码的生成。这就是编译时的符号处理。
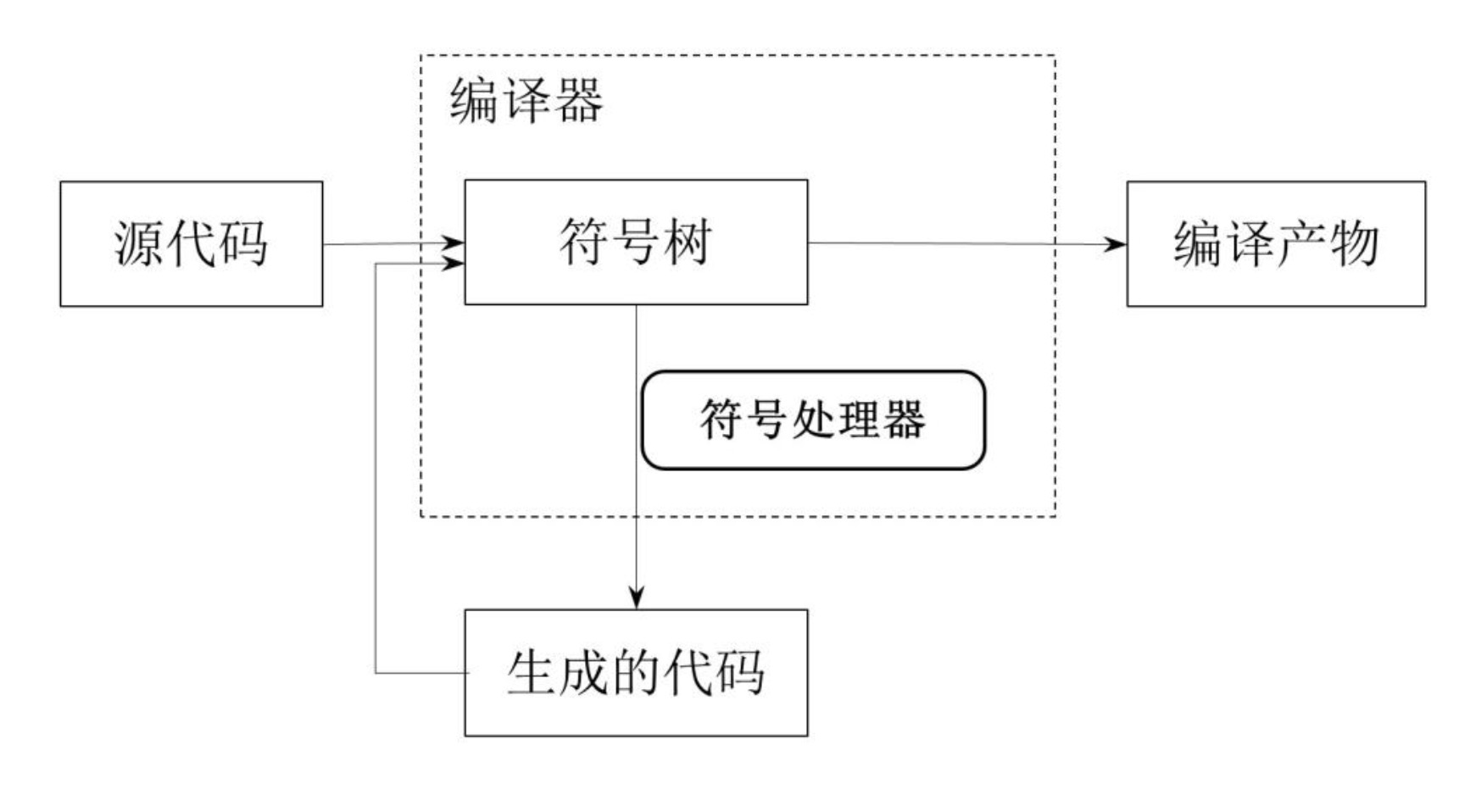
符号的基本概念
Java 的符号
Java 的符号包括变量(VarSymbol)、方法(MethodSymbol)、 类(ClassSymbol)、包(PackageSymbol)等等
Java 编译器提供了一套完善的符号处理的机制,即APT(Annotation Processing Tool,注解处理器)。不过,APT 的公开 API 当中并没有提到 Symbol,这是怎么回事呢?
这是因为 Java 编译器的设计者不希望暴露过多编译器内部的细节,基于符号的实现抽象出了以 Element 类型为基础的公开 API。
需要注意的是,Java 符号并不等同于 Java 抽象语法树(Abstract Syntax Tree, 缩写为 AST)节点,Java 语法树的节点类都是 JCTree 的子类,其中 JC 代表 Javac。与 Symbol 和 Type 相同,JCTree 也是 Java 编译器的内部实现,我们只需要清楚 Java 符 号是基于 Java 语法树创建出来的,它只包含语法树结构当中的类、方法、变量等结构,但不包含函数体、表达式内容等信息即可。
Kotlin 的符号
Kotlin 的符号在 Google 的开源项目 KSP(Kotlin Symbol Processing,Kotlin 符号处理)当中给出,该项目目前已经成为 Kotlin 官方推荐的符号处理方案。
Kotlin 目前存在两套语法树实现,即 FE1.0 的 PSI 和 K2 编译器当 中的 FIR。与 Java 不同,Kotlin 的语法树的 API 并不算是严格意义的 内部 API,因为这些 API 已经被大量应用在编译器插件和 IntelliJ 插件的实现当中了。不过,由于 Kotlin 编译器还在不断地重写过程中,因此抽象出 Kotlin 符号的概念来屏蔽 Kotlin 编译器的内部实现显然是一个更好的选择,这与 APT 的实现如出一辙。
Kotlin 符号的实现依赖于语法树的实现,二者从命名和用法上也有着非常接近的地方。Kotlin 的符号类型都实现自 KSNode 接口,例如类符号 KSClassDeclaration,函数符号KSFunction,等等,这些对应于 APT 当中的 Element 接口及其实现类。
与 Java 符号相同,Kotlin 的符号也是基于语法树节点构造出来的,只包含类、函数、 变量这样的符号信息,而不包含函数体、语句、表达式内容等等。
符号与语法树节点的关系和区别
前面已经提到,符号是基于语法树构造出来的,它只包含语法树当中的部分信息。确切地说,符号只包含程序的 ABI(Application Binary Interface,二进制接口)信息。
如果我们希望检查函数的命名是否符合代码规范,可以基于对符号的处理设计实现方案。但如果我们希望检查的是局部变量,那么只处理符号可能就有些力不从心了,因为符号当中只包含 类的成员变量而不包含局部变量。
处理器的基本结构
APT 的基本结构
- 初始化
- 声明和配置处理器参数
- 声明处理器支持的注解类型
- 声明处理器支持的 Java 源码版本
- 核心处理方法
KSP 的基本结构
KSP 的处理器只有三个函数:
- finish: 在处理器执行完成时调用。如果有需要关闭的资源,可以在这里处理。
- onError: 处理器执行过程中遇到错误,在执行完毕之后调用。
- process: 提供处理器的核心实现,通过读取符号信息,处理代码分析或者文件生成等逻辑。
APT 与 KSP 的处理器的结构差异
KSP 没有像 APT 那样要求处理器明确给出支持的源码版本、注解类型和参数。KSP 的版本是与 Kotlin 编译器的版本绑定的,其中隐含了支持的最新的 Kotlin 源码版本。
APT 需要在处理器实现当中声明支持的注解类型,Java 编译器会在调用处理器之前根据源 码的实际情况来决定是否调用该处理器。相比之下,KSP 似乎并没有打算把自己限制于对注解的 处理范围之内。尽管它提供了很多与 APT 相似的 API,但在 KSP 当中直接获取所有的符号进行分析处理似乎是顺理成章的。
APT 要求在处理器当中声明需要的参数,这样使用者就能更清楚地知道处理器需要哪些参数。 然而,APT 没有对参数的传递做强制要求,因此不能对使用者形成有效的引导和约束。KSP 干 脆不要求处理器对参数做声明,处理器的开发者只需要在文档当中对参数做好说明并在处理器当中处理好参数缺省的情况即可。
处理器的配置文件
在了解了处理器的基本结构之后,我们还需要通过配置文件将处理器接入到编译流程当中, 让编译器在编译时可以加载并执行它们。由于 Java 和 Kotlin 编译器都是 JVM 程序,因此配置文件需要放到编译器运行时的 classpath 当中。
深入符号和类型
本节介绍如何获取符号当中的信息,这也是符号处理过程当中最核心的内容。
获取修饰符
获取符号的修饰符,在 APT 当中可以使用 Element#getModifiers(),这个方法适用于所有符号,因此如果我们希望判断一个类是不是公有的,只需要判断它的修 饰符集合当中是否包含 PUBLIC。
在 KSP 当中同样有类似的 API,即 KSModifierListOwner#modifiers,用法与 APT 类似。
通过名称获取相应的符号
在 APT 当中,我们可以使用 Elements#getTypeElement(CharSequence) 获取参数对应的符号,其中 Elements 的实例可以通过 ProcessingEnvironment 获取。
在 KSP 当中,可以通过 Resolver#getClassDeclarationByName(String) 来获取类符号,参数也可以是 KSName 类型。
我们还可以使用 Resolver#getFunctionDeclarationsByName(String, Boolean) 获取函数符号,使用Resolver#getPropertyDeclarationByName(String, Boolean) 来获取属性符号。
获取符号的类型
在 APT 当中,任何符号都可以通过 Element#asType() 方法来获取它的类型,返回值类型为 TypeMirror。
在 KSP 当中获取符号的类型也很容易。主要有两种情况,一种是通过类符号直接获取类型,另一种是通过类型引用符号解析类型。
那么,KSP 为什么要这么设计呢?
因为类型引用符号与其他符号一样,是源代码的直接表示,无需通过语义分析就可以获取到; 而解析类型引用符号是在所有类型中查找所引用的类型的过程,这个过程需要依赖语义分析的结果,有一定的开销。KSP 当中引入类型引用符号,使得类型的解析延迟到使用时,也是一种性能 上的优化。
通过类型获取符号
一个类型只有在代码当中定义之后才会出现在类型系统当中,因而任何类型都可以找到它对应的符号。
在 APT 当中,想要通过 TypeMirror 获取它对应的 Element,需要借助 Types#asElement() 方法,其中 Types 的实例可以在处理器的 init 方法当中通过 ProcessingEnvironment 获取。
在 KSP 当中,获取类型对应的符号可以直接使用 KSType#declaration。
判断类型之间的关系
类型之间存在相同(Same)、可赋值(Assignable)、子类型(Subtype)等关系。
相同类型
相同类型很容易理解,在 APT 当中可以使用 Types#isSameType(TypeMirror,TypeMirror) 来判断两个 TypeMirror 实例是否是相同的类型。
在 KSP 当中,判断两个类型是否相同非常直接,使用 equals 运算符即可。
可赋值类型和子类型
可赋值类型和子类型的表述在 Kotlin 当中没有实质的区别,即在 Kotlin 当中如果类 型 A 的实例可以赋值给类型 B 的变量,那么 A 类型就是 B 类型的子类型。
不过在 Java 当中,可赋值类型和子类型却不完全相同。尽管我们也经常通过两个类型是 否可赋值来判断二者之间是否存在子类型关系,不过在 Java 当中这并不是绝对的。
因此,我们可以看到 APT 当中,Types 提供了 isAssignable 来判断类型的可赋值关 系,以及 isSubtype 来判断类型的父子关系。而在 KSP 当中就比较简单了,KSType 只有一个 isAssignableFrom 来判断类型的可赋值关系。
获取注解及其参数值
我们可以通过符号获取到标注于它之上的注解,并进而获取到其中的值。
如果使用 APT 来处理这段代码,我们可以通过 RoundEnvironment 和注解符号直接获取到被注解标注的符号,通过这些符号再获取注解的参数。如果注解处理器的运行时可见,我们可以直接使用 getElementsAnnotatedWith 来获取注解的参数。
KSP 当中同样也存在这两种相似的做法。如果注解在处理器运行时不可见,我们同样需要通过处理符号来获取注解的信息。
深入理解符号处理器
如何使用 APT 处理 Kotlin 符号
在 KSP 发布之前,我们通常会使用 APT 来实现 Kotlin 的符号处理需求。Kotlin 编译器提供一个专门的插件来实现这个需求,即 KAPT(Kotlin Annotation Processing Tool)
Kotlin 编译器会先将 Kotlin 的源码转成 Java 编译器可以处理的 Java 存根,再由 Java 编译器执行原本的符号处理逻辑。
当然 Java 存根中会丢失很多 Kotlin 的语法特性,这种场景下,我们就需要借助 Metadata 注解的信息来实现 Kotlin 符号的还原了
处理器的轮次和符号的延迟处理
符号处理器会被调用多次,这主要是因为处理器调用时通常会有新的源码产生,这些源码也需要经过处理器处理。
在 APT 当中,处理器的执行有两个条件,满足其一就会被执行:
- 当前轮次的源码当中存在被该处理器声明的注解所标注的符号。
- 该处理器在之前的轮次当中已经被执行过。
AP 处理器执行时,process 方法的参数 roundEnv 包含了当前轮次所需要处理的符号信息,这些符号信息源自于编译器的输入(首轮执行处理器)或者上一轮次生成的源代码或者二进制类 文件(后续执行处理器)。
在 KSP 当中,处理器的 process 方法在每个轮次都会被执行。KSP 默认就对符号验证和延迟处理当前无法解析的符号做了支持,这使得符号处理的逻辑变得更加简单直接。与 APT 不同,KSP 的 process 的返回值就是需要延迟处理的符号,因此如果遇到无法通过验证的符号,我们只需要将其作为返回值返回即可。
处理器对增量编译的支持
增量编译要求在编译过程中尽可能的减少对源文件的处理。生成的目标文件与源文件之间的关系可以分为两种:
- 目标文件只依赖于若干特定的源文件,除了这些源文件之外的其他变动不会影响目标文件的生成,简称为一对一或特定多对一。
- 目标文件依赖于多个源文件,新的源文件或者其他源文件的改动都可能会影响到目标文件的生成,简称为不定多对一。
APT 支持以下几种处理器的增量编译模式:
- 隔离模式(Isolating):该模式下每一个被注解标注的符号必须独立地生成目标文件,处理过程当中只能访问与该符号有关的其他符号和类型,包括父类型、成员符号和类型等等。该模式要求源文件与目标文件之间遵从一对一的对应关系。
- 聚合模式(Aggregating):在该模式下,Gradle 将总是重新调用该处理器对相应的符号进行处理,并且对生成的文件进行编译,即不定多对一。
显然,隔离模式的限制更多,但更容易实现增量编译;聚合模式限制较少,但往往会影响编译速度。
KSP 当中存在类似的设计。KSP 的增量编译默认是开启的,我们只需要在创建目标文件时明确源文件和目标文件的关系即可。
当 Dependencies 的 aggregating 为 true 时,目标文件与源文件之间是聚合的多对一关系。在 Dependencies 当中的文件变更以及有新增文件时,处理器会被重新执行,这种 情况与 APT 的聚合模式类似。
如果 aggregating 为 false,则只有 Dependencies 当中包含的文件变更时处理器才会被重新执行,这种情况与 APT 的隔离模式类似。此时,KSP 允许多个确定的源文件对应到 一个目标文件上,除了这些源文件之外的任何变更都不会引起对应的处理器的执行。这种情况下,源文件与目标文件是一对一或者特定多对一的关系。
尽管工作机制类似,但 KSP 比 APT 的增量支持做得更精细。我们可以在同一个 Kotlin 符号处理器当中为不同的目标文件配置不同的依赖关系,但 APT 的每一个处理器却只能配置一 种增量编译的模式。
多模块的符号处理
如果源文件到目标文件的映射关系是一对一或者特定多对一的隔离模式,那么多模块与单模块在符号处理时没有任何区别。这种情况下,各个模块单独处理各自的符号,模块之间不会产生影响。
但如果源文件到目标文件的映射关系是不定多对一的聚合模式,那么情况就可能会变得复杂。
由于被标注的符号可能分散在各个模块当中,因此我们在单个模块编译时无法直接生成目标文件。为了解决这个问题,我们需要引入主从模块的概念,主模块和从模块当中都可能会存在被标注的符号,但最终的目标文件生成在主模块当中统一完成。
主模块完成最终的目标文件生成,那么从模块似乎什么都不用做,是这样吗?当然不是。不管是 APT 还是 KSP,都只能直接获取到当前轮次需要编译的源代码当中被注解标注的符号,这意味着在主模块编译时,它依赖的从模块当中被注解标注的符号不能被直接获取到的。为了解决主模块获取从模块符号的问题,我们通常会在从模块当中生成一个包含从模块当中被注解标注的符号信息的文件,称为元信息文件。
通常情况下我们会把这个元信息文件生成到一个特定的包名下,这样在主模块的处理器当中,我们就可以通过包名来获取所有的元信息类。