编译器 1:语法分析
本章介绍为Jack 语言构建编译器。
编译器是一种程序,能将高级语言程序从源语言翻译成目标语言。这个翻译过程(即编译,compilation)从概念上讲由两个不同的任务组成。
- 首先,我们必须理解源程序的语法(syntax),以此来揭示程序的语义(semantics)。比如,对代码进行语法分析可得知程序想要声明数组或操纵对象。该信息让我们能够使用目标语言的 语法来重构程序的逻辑。第一个任务通常称为语法分析(syntax analysis)
- 第二个任务,即代码生成(code generation)
背景知识
典型的编译器由两个主要模块组成:语法分析(syntax analysis)模块和代码生成(code generation)模块。语法分析任务通常可以进一步分成两个模块:
- 字元化(tokenizing):模块将输入的字符分组成语言原子元素(language atoms):
- 然后由语法分析 (parsing)模块将所得到的语言原子元素集合同语法规则相匹配。
词法分析
程序最简单的语法形式就是存储在文本文件中的一系列字符。对程序进行语法分析的第一步,是将字符分组成字元(由语言语法所定义),忽略空格和注释。这一步通常称为词法分析 (lexical analysis)、扫描(scanning)或字元化 (tokenizing)。一旦程序被分组成字元,字元(而不是字符)就被看作程序的基本原子,字元集合就成为编译器的输入。
语法
一旦对程序进行语法分析,形成一系列字元(即字元流,token stream),就面临更具挑战性的任务,即将字元进行分析,理解成对应的规范结构。换句话说,必须想办法考虑如何将这些字元分组成变量声明、语句、表达式等等的语言结构。通过将字元集合按照预定义的规则集(set of rules),即语法(grammar)进行组合匹配,就可以实现分组和分类任务。
几乎所有的编程语言,以及大多数用于描述复杂文件类型语法的其他的形式语言,都可以使用上下文无关语法 (context-free grammars)来描述。上下文无关语法是一组规则,用来指定语言中的语法元素如何由更简单的元素组成。
比如,Java 语法允许将基本元素 100、count 和 <= 联合成表达式 count<=100。同样的,Java 语法允许确定文本 count<=100 是正确的Java表达式。事实上,每种语法都可以从两个方面来考察。从声明的观点来看,语法规定了可行的方案,来将字元(token,也称终结符,terminals)组合成更高级的语法元素(也称为非终结符,non-terminals)。从分析的观点来看,语法是用于执行反向任务的规则:将给定的输入,即通过字元化阶段(tokenizing phase)得到的字元集合,解析成非终结符、较低级的非终结符,以及最后不能继续分解的终结符。
语法分析
检查语法是否将所输入的文本看作合法输入,这个过程称为语法分析(parsing)。正如前面提到的,“分析给定的文本”意味着,决定文本和给定语法规则之间的一致性。因为语法规则是分层的,所以语法分析器(parser)生成的输出可以用称 语法分析树(parse tree)或导出树(derivation tree)的树状数据结构来描述。
递归下降分析(Recursive Descent Parsing):自顶向下的方法,也称为递归下降分析,是应用由语法规则描述的嵌套结构来尝试递归地分析字元集合形成的输入流(token stream)。现在来考虑如何编写实现该功能的语法分析器程序(parser program)。对于语法中每个描述非终结符的规则,可以为语法分析器程序配备递归子程序,该子程序用米递归地分析非终结符。如果非终结符仅由终结符原子构成,该程序就很容易处理它们。否则,对于规则右边的每个非终结符构建块(building block),程序可以递归地调用“分析该非终结符”的程序。整个处理过程递归进行,直到所有终结符原子元素全部被处理完毕。

LL(0)语法:递归分析算法是简单高效的算法。唯一可能的复杂性在于分析的非终结符有多种可选的解释。例如,当 parsestatement()试图分析一条语句时,它预先不知道该语句是 while-语句、if-语句还是用花括号括起来的一串语句。可能性的范围由语法来决定,在某些情况下很容易辨别是哪一种选择。我们的观点可归纳如下:每当一个非终结符有多种可选择的导出规则时,其第一个字元足以确定该非终结符所属的表达式类型,而不会出现不确定的情况。具有这种属性的语法称为 LL(O)。递归下降算法可以简洁明了地处理这类语法。
规范详述
Jack 语法规范有如下约定

Jack 语言语法


实现
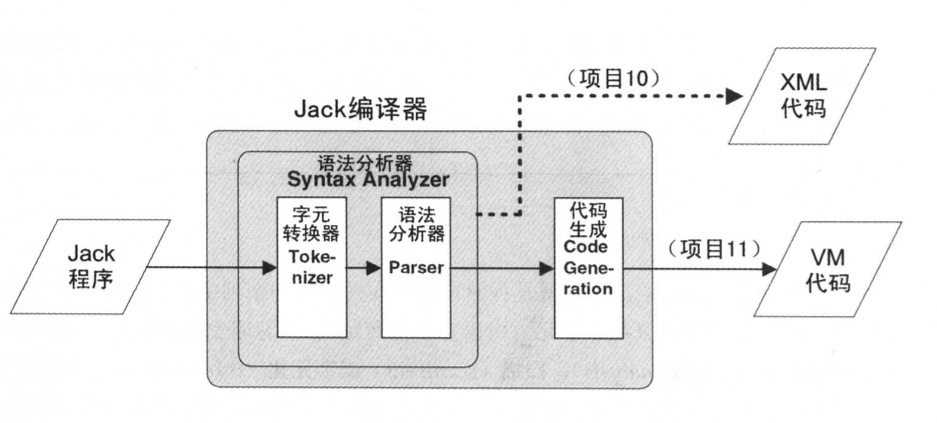
本节将给出语法分析器的软件架构。建议将实现分成三个模块:
- JackAnalyzer: 建立和调用其他模块的项层驱动模块
- JackTokenizer: 字元转换器(字元化)模块
- CompilationEngine: 自项向下的递归语法分析器。