虚拟机 1:堆栈运算
虚拟机的基本思想如下所述:中间代码运行在虚拟机 (Virtual Machine) 上,而不是真实的硬件平台上。
VM是并不真实存在的抽象计算机,但是却能在其他的计算机平台上得以实现。为什么这种思想极具意义,有很多原因,其中一个原因在于代码的可移植性。因为VM 能够在多目标平台上相对轻松地实现,因此基于 VM 的软件不经过修改源代码就可以在不同的处理器和操作系统上运行。
背景知识
虚拟机泛型
高级语言程序能够在目标计算机上运行之前,它必须被翻译成计算机的机器语言。
这个翻译工作是相当复杂的过程。通常,必须对任意给定的高级程序和其对应的机器语言编写专用的编译器。每种编译器编译的高级语言与编译之后的机器语言之间存在很强的依赖性。减少这种依赖性的方法之一是,将整个编译过程划分成两个几乎独立的阶段。在第一个阶段,高级程序被解析出来,其命令被翻译成一种中间处理结果——既不是“高级”也不是“低级”的中间结果。在第二个阶段,这些中间结果被进一步翻译成目标硬件的机器语言。
从软件工程的角度来分解是非常吸引人的:第一阶段仅依赖于源高级语言的细节,第二阶段仅依赖于目标机器语言的细节。当然,两个编译阶段之间的接口(接口就是中间处理步骤的精确定义)必须仔细地进行设计。实际上,该接口的重要性之高,甚至应该将其单独定义为一种抽象计算机的语言。其实我们可以明确地描述这种虚拟机(wirtualmachine),其指令就是由高级命令分解而成的中间处理步骤。原来作为一个独立程序的编译器现在被分成两个独立的程序。第一个程序,仍然称为编译器(compiler),将高级代码翻译成中间 VM指令,第二个程序将这个 VM 代码翻译成目标计算机硬件平台(简称“硬件平台”)的机器语言。
明确且正式的虚拟机语言概念有很多务实的优点。首先,仅需要替换虚拟机实现部分(有时候称为编译器的后端程序,backend)就能相对容易地得到不同硬件平台的编译器。因此,虚拟机在不同硬件平台之间的可移植性可以实现代码效率、硬件成本和程序开发难度之间的权衡。其次,很多语言的编译器能够共享 VM 后端程序,允许代码共享和语言互用性。比如,某种高级语言善于科学计算,而另一种在处理用户接口方面很突出。如果把两种语言编译到通用的VM层,那么通过使用约定的调用语法,其中一种语言的程序就能够很容易地调用另一种语言的程序。
堆栈机模型
像很多程序语言一样,VM 语言包含算术操作、内存访问操作、程序流程控制操作和子程序调用操作。有很多软件实体可作为VM 语言的实现,但在选择中要考虑的关键是:在 VM操作中的操作数和结果应该驻留在哪里。
也许最“最干净利落”的解决方法是将其放在堆栈(stack)数据结构里面。在堆栈机(stack machine)模型里,算术命令将其操作数从堆栈顶弹出,并将结果从栈顶压入。其他的命令将数据项从堆栈顶弹出,并转移到指定的内存单元,或反向操作之。经证明,这些简单的堆栈操作可以被用来计算任何数学或逻辑表达式。此外,任何程序,不管它用哪种程序语言编写,都能被翻译成等价的堆栈机语言。这样的堆栈机模型能被应用在 Java 虚拟机和接下来要介绍和构建的 VM上。
VM 规范详述(第一部分)
概论
虚拟机是基于堆栈的(stack-based):所有的操作都在堆栈上完成。它也是基于函数的(function-based):一个完整的、应用 VM 语言编写的 VM 程序由若干个称函数(functions)的程序单元组成,这些函数使用VM 语言编写。每个函数都有自己独立的代码,并被独立地处理。VM 语言使用单一的16位数据类型,它能够表示整数、布尔类型,或者指针。该语言包含四种类型的命令:
- 算术命令: 在堆栈上执行算术和逻辑操作。
- 存储器存取命令: 在堆栈和虚拟内存单元之间转移数据。
- 程序流程命令: 使条件分支操作和无条件分支操作变得容易。
- 函数调用命令: 调用函数并返回调用处(即函数调用指令的下一条指令地址)。
构建虚拟机是一件复杂的事情,所以我们把它分成了两个阶段。在本章里我们详细介绍算术命令和内存访问命令,构建仅实现这两种命令的基本 VM 翻译器。下一章将会详细介绍程序流程控制和函数调用命令,然后将我们构建好的翻译器扩展成一个包含所有这四种命令的虚拟机。
算术命令和逻辑命令

内存访问命令
在本章的前面介绍中,内存访问命令使用伪命令pop 和 push x 来表示,这里符号x代表在某个全局内存中的一个独立的存储单元。然而为了保留语义信息,VM 需要操纵 8 个独立的虚拟内 存段。

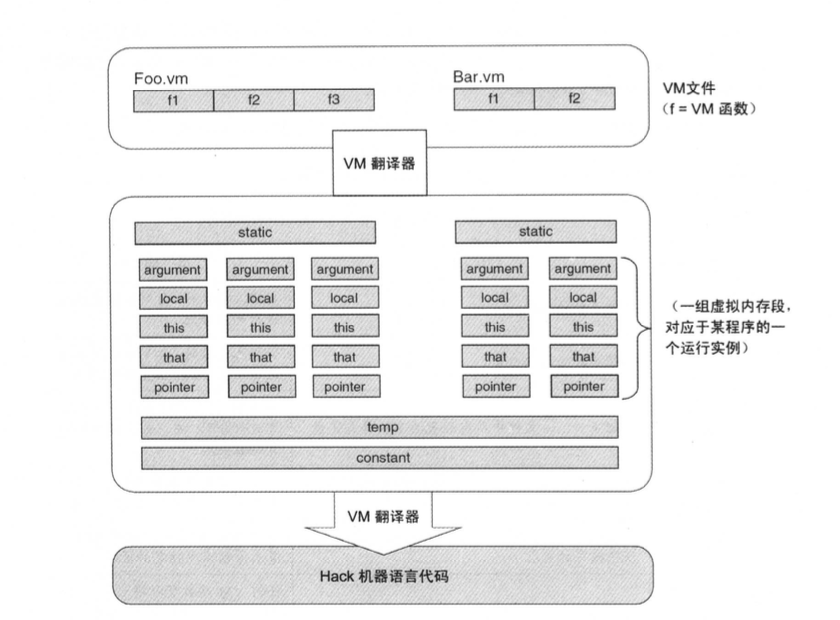
除了这8个虚拟内存段可被 VM的 pop 和 push 直接操作,VM还操纵两个暗含的数据结构称为堆栈(stack)和堆(heap)。这些数据结构从来不会被直接提到,但随着VM对它们进行操作,它们的状态却会在后台变化。
- 堆栈(stack): 考虑两条连续的命令语句 push argument 2 和 pop 1ocal 1。这样的 VM 操作的工作内存就是堆栈。数据值并不是简单地直接从一个单元跳到另一个单元,而是必须经过堆栈中转。尽管堆栈是 VM结构中的核心角色,但是在VM 语言中从未显式地体现出它的功能。
- 堆(heap): 处在 VM 后端的另一个数据结构就是堆。堆是RAM 区域的名字,用来存储对象和数组数据。这些对象和数组能够通过VM命令来操纵。
Jack-VM-Hack 平台中的程序要素

实现
Hack 计算机的数据内存由32K个 16-位字组成。前16K 作为通用RAM。下一个16K 包含 1/O 设备的内存映像。VM 实现应该使用如下的间隔分配方式:


- local,argument,this,that :每一个这样的段都被直接映射到 RAM;通过专用寄存器(分别为 LCL、ARG、THIS、THAT)来保存,其物理基地址,就可以维持其在RAM 中的位置。如此一来,对这些段的第;个数据项的访问,应该被翻译成“获取 RAM 中地址为 (base+i) 的值的汇编代码,这里 base是存储在各段专有寄存器中的当前值。
- pointer, temp :这些段被直接映射在 RAM中的一个固定区域上。pointer段被映射在 RAM位置3~4(也称內 THIS 和 THAT)上,temp 段被映射在 RAM位置5~12(也称为R5,R6.R12)上。因此访问 point i 应该被翻译成访问 RAM位置3+i 的汇编代码,访问 temp i应该被翻译成访问 RAM 位置5+i 的汇编代码。
- Constant:这个段是真正虚拟的,因为它不占用目标平台上的任何物理存储空间。VM实现通过简单地提供常数i来处理任何VM对
的访问。 - static :根据Hack 机器语言规范,在汇编程序中每遇到一个新的符号时,编译器就为其分配一个新的RAM单元,从地址16处开始。利用这个规定,使用汇编语言符号f.j来表示VM文件王中的每个静态变量数字j。例如,假设文件 xxx.vm包含命令push static 3。该命令能被翻译成Hack 汇编命令exxx.3 和D=M,接下来的汇编代码将D的值压入堆栈。该static 段的实现方式有点机巧诡异,但确实起作用。

程序结构
- Parser:分析.vm 文件,封装对输入代码的访问。它读取 VM命令并解析,然后为它们的各个部分提供方便的访问入口。除此之外,它还移除代码中所有的空格和注释。
- CodeWriter:将VM命令翻译成 Hack 汇编代码。
- 主程序:主程序应该构造一个 Parser 和一个 codevriter ;Parser 用来解析 VM输入文件;codewriter 用来将生成的 hack 汇编代码写入相应的输出文件.asm 文件中。另外,主程序应该读取输入文件中的每一条命令并为其生成对应的汇编代码。