内存
最近在读《程序员的自我修养:链接,装载与库》,其实这本书跟 Android 开发的联系还挺紧密的,无论是 NDK 开发,或者是性能优化中一些常用的 Native Hoook 手段,都需要了解一些链接,装载相关的知识点。本文为读书笔记。
程序的内存布局
现代的应用程序都运行在一个内存空间里,在 32 位的系统里,这个内存空间拥有 4GB(2的32次方)的寻址能力。
大多数操作系统都会将 4GB 的内存空间中的一部分挪给内核使用,应用程序无法直接访问这一段内存,这一部分内存地址被称为内核空间。Linux 默认情况下会将高地址的 1GB 空间分配给内核,用户使用的剩下 3GB 的内存空间称为用户空间。
一般来说,应用程序使用的内存空间里包括如下“默认”的区域:
- 栈:栈用于维护函数调用的上下文,离开了栈函数调用就没法实现。栈通常在用户空间的最高地址处分配,通常有数兆字节的大小。
- 堆:堆是用来容纳应用程序动态分配的内存区域,当程序使用 malloc 或 new 分配内存时,得到的内存来自堆里。堆通常存在于栈的下方(低地址方向),在某些时候,堆也可能没有固定统一的存储区域。堆一般比栈大很多,可以有几十至数百兆字节的容量。
- 可执行文件映像:这里存储着可执行文件在内存里的映像,由装载器在装载时将可执行文件的内存读取或映射到这里。
- 保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称,例如,大多数操作系统里,极小的地址通常都是不允许访问的,如NULL。通常 C 语言将无效指针赋值为0也是出于这个考虑,因为0地址上正常情况下不可能有有效的可访问数据。

如图所示,栈向低地址增长,堆向高地址增长。当栈或堆现有的大小不够用时,它将按照图中的增长方向扩大自身的尺寸,直到预留的空间被用完为止。
栈
什么是栈
栈(stack)是现代计算机程序里最为重要的概念之一,几乎每一个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今能够看见的所有的计算机语言。在解释为什么栈会如此重要之前,让我们来先了解一下传统的栈的定义:
在经典的计算机科学中,栈被定义为一个特殊的容器,用户可以将数据压入栈中(入栈,push),也可以将已经压入栈中的数据弹出(出栈,pop),但栈这个容器必须遵守一条规则:先入栈的数据后出栈(First In Last Out, FIFO),即先进后出。
而在操作系统中,栈则是一个具有以上属性的动态内存区域。程序可以将数据压入栈中,也可以将数据从栈顶弹出。压栈操作使得栈增大,而弹出操作使栈减小。在经典的操作系统里,栈总是向下增长的。
栈在程序运行中具有举足轻重的地位。最重要的,栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧(Stack Frame)或活动记录(Activate Record)。堆栈帧一般包括如下几方面内容
- 函数的返回地址和参数
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。
- 保存的上下文:包括在函数调用前后需要保持不变的寄存器。
在i386中,一个函数的活动记录用 ebp 和 esp 这两个寄存器划定范围。esp 寄存器始终指向栈的顶部,同时也就指向了当前函数的活动记录的顶部。而相对的,ebp 寄存器指向了函数活动记录的一个固定位置,ebp 寄存器又被称为帧指针(Frame Pointer)。一个很常见的活动记录示例如图所示:
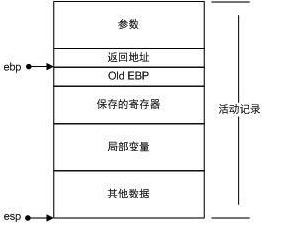
- 在参数之后的数据(包括参数)即是当前函数的活动记录。
- ebp 固定在图中所示的位置,不随这个函数的执行而变化,相反地,esp始终指向栈顶,因此随着函数的执行,esp会不断变化。
- 固定不变的ebp可以用来定位函数活动记录中的各个数据。在ebp之前首先是这个函数的返回地址,它的地址是ebp-4,再往前是压入栈中的参数,它们的地址分别是ebp-8、ebp-12等,视参数数量和大小而定。
- ebp所直接指向的数据是调用该函数前ebp的值,这样在函数返回的时候,ebp可以通过读取这个值恢复到调用前的值。
函数调用的过程
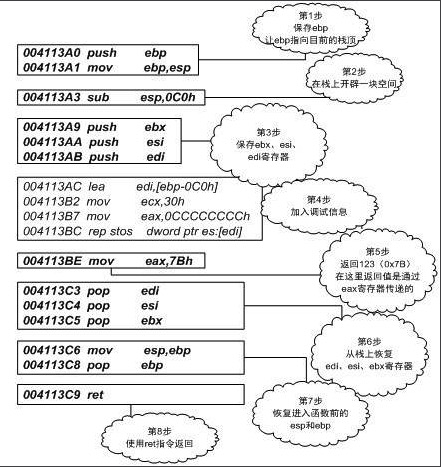
之所以函数的活动记录会形成如上的结构,是因为函数调用本身是如此书写的:一个i386下的函数总是这样调用的:
- 把所有或一部分参数压入栈中,如果有其他参数没有入栈,那么使用某些特定的寄存器传递。
- 把当前指令的下一条指令的地址压入栈中。
- 跳转到函数体执行。
其中第 2 步和第 3 步由指令call一起执行。跳转到函数体之后即开始执行函数,而i386函数体的“标准”开头是这样的:
- push ebp:把 ebp 压入栈中(称为old ebp)。
- mov ebp, esp:ebp = esp(这时ebp指向栈顶,而此时栈顶就是old ebp)。
- 【可选】sub esp, XXX:在栈上分配XXX字节的临时空间。
- 【可选】push XXX:如有必要,保存名为XXX寄存器(可重复多个)。
把 ebp 压入栈中,是为了在函数返回的时候便于恢复以前的 ebp 值。而之所以可能要保存一些寄存器,在于编译器可能要求某些寄存器在调用前后保持不变,那么函数就可以在调用开始时将这些寄存器的值压入栈中,在结束后再取出。而在函数返回时,所进行的“标准”结尾与“标准”开头正好相反
- 【可选】pop XXX:如有必要,恢复保存过的寄存器(可重复多个)
- mov esp, ebp:恢复ESP同时回收局部变量空间。
- pop ebp:从栈中恢复保存的ebp的值。
- ret:从栈中取得返回地址,并跳转到该位置。
堆与内存管理
什么是堆
光有栈对于面向过程的程序设计还远远不够,因为栈上的数据在函数返回的时候就会被释放掉,所以无法将数据传递至函数外部。而全局变量没有办法动态地产生,只能在编译的时候定义,有很多情况下缺乏表现力。在这种情况下,堆(Heap)是唯一的选择。
堆是一块巨大的内存空间,常常占据整个虚拟空间的绝大部分。在这片空间里,程序可以请求一块连续内存,并自由地使用,这块内存在程序主动放弃之前都会一直保持有效。
当程序使用 malloc 或 new 分配内存时,得到的内存来自堆里。那么malloc到底是怎么实现的呢?
有一种做法是,把进程的内存管理交给操作系统内核去做,既然内核管理着进程的地址空间,那么如果它提供一个系统调用,可以让程序使用这个系统调用申请内存,不就可以了吗?
这种方式的问题在于性能比较差,因为每次程序申请或者释放堆空间都需要进行系统调用。我们知道系统调用的性能开销是很大的,当程序对堆的操作比较频繁时,这样做的结果会严重影响程序的性能。比较好的做法就是程序向操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间,而具体来讲,管理着堆空间分配的往往是程序的运行库。
运行库相当于是向操作系统“批发”了一块较大的堆空间,然后“零售”给程序用。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。当然运行库在向程序零售堆空间时,必须管理它批发来的堆空间,不能把同一块地址出售两次,导致地址的冲突。于是运行库需要一个算法来管理堆空间,这个算法就是堆的分配算法。
不过在了解具体的分配算法之前,我们先来看看运行库是怎么向操作系统批发内存的。
Linux 进程堆管理
Linux 提供了两种堆空间分配方式,即两个系统调用:一个是 brk() 系统调用,另一个是 mmap()。
brk() 的作用实际上就是设置进程数据段的结束地址,即它可以扩大或者缩小数据段(Linux 下数据段和 BSS 合并在一起统称数据段)。如果我们将数据段的结束地址向高地址移动,那么扩大的那部分空间就可以被我们使用,把这块空间拿来作为堆空间是最常见的做法之一。
mmap() 的作用就是向操作系统申请一段虚拟地址空间,当然这块虚拟地址空间可以映射到某个文件(这也是这个系统调用的最初的作用),当它不将地址空间映射到某个文件时,我们又称这块空间为匿名(Anonymous)空间,匿名空间就可以拿来作为堆空间。
glibc 的 malloc 函数是这样处理用户的空间请求的:对于小于 128KB 的请求来说,它会在现有的堆空间里面,按照堆分配算法为它分配一块空间并返回;对于大于 128KB 的请求来说,它会使用 mmap() 函数为它分配一块匿名空间,然后在这个匿名空间中为用户分配空间。
堆分配算法
前面介绍了堆在进程中的地址空间是如何分布的,对于程序来说,堆空间只是程序向操作系统申请划出来的一大块地址空间。而程序在通过malloc申请内存空间时的大小却是不一定的,从数个字节到数个GB都是有可能的。
于是我们必须将堆空间管理起来,将它分块地按照用户需求出售给最终的程序,并且还可以按照一定的方式收回内存。其实这个问题可以归结为:如何管理一大块连续的内存空间,能够按照需求分配、释放其中的空间,这就是堆分配的算法。
下面介绍一些简单的堆分配算法:
- 空闲链表:空闲链表(Free List)的方法实际上就是把堆中各个空闲的块按照链表的方式连接起来,当用户请求一块空间时,可以遍历整个列表,直到找到合适大小的块并且将它拆分;当用户释放空间时将它合并到空闲链表中。
- 位图:其核心思想是将整个堆划分为大量的块(block),每个块的大小相同。当用户请求内存的时候,总是分配整数个块的空间给用户,第一个块我们称为已分配区域的头(Head),其余的称为已分配区域的主体(Body)。而我们可以使用一个整数数组来记录块的使用情况,由于每个块只有头/主体/空闲三种状态,因此仅仅需要两位即可表示一个块,因此称为位图。
- 对象池:对象池的思路很简单,如果每一次分配的空间大小都一样,那么就可以按照这个每次请求分配的大小作为一个单位,把整个堆空间划分为大量的小块,每次请求的时候只需要找到一个小块就可以了。对象池的管理方法可以采用空闲链表,也可以采用位图,与它们的区别仅仅在于它假定了每次请求的都是一个固定的大小,因此实现起来很容易。由于每次总是只请求一个单位的内存,因此请求得到满足的速度非常快,无须查找一个足够大的空间。
实际上很多现实应用中,堆的分配算法往往是采取多种算法复合而成的。比如对于 glibc 来说,它对于小于 64 字节的空间申请是采用类似于对象池的方法;而对于大于 512 字节的空间申请采用的是最佳适配算法;对于大于 64 字节而小于 512 字节的,它会根据情况采取上述方法中的最佳折中策略;对于大于 128KB 的申请,它会使用 mmap 机制直接向操作系统申请空间。
总结
内存是程序运行的基础运行环境之一,了解程序如何使用内存,对于程序本身的理解也非常重要,本文主要包括以下内容:
- 介绍了 i386 体系结构下程序的基本内存布局
- 什么是栈,以及栈在函数调用过程中的作用
- 什么是堆,Linux 进程的堆管理机制,以及主要的堆分配算法