Native Hook 快速上手
前言
Hook 原意是指钩子,它表示的就是在某个函数的上下文做自定义的处理来实现我们想要的黑科技
大家可能比较熟悉 Java 层的一些 Hook 技术,比如反射,动态代理,或者 ASM 字节码插桩
在 Java 层之外,Android 系统还有很大一部分属于 Native 层,有时不可避免的需要用到 Native Hook 技术
本文主要介绍 Native Hook 是什么,以及如何通过一个例子快速上手
Native Hook 是什么?
Native Hook 技术通常有以下两种实现方式
- PLT Hook:通过修改 GOT 表,将目标函数的地址指向自定义的 Hook 函数的地址,从而拦截和修改目标函数的行为。
- Inline Hook:直接将函数开始处的指令更替为跳转指令,使得原函数直接跳转到 Hook 的目标函数函数
我们下面来分别介绍一下
PLT Hook
PLT Hook 用一句描述就是:通过修改 GOT 表,将目标函数的地址指向自定义的 Hook 函数的地址,从而拦截和修改目标函数的行为。那么 GOT 表是什么呢?这需要我们对 SO 库文件的 ELF 文件格式和动态链接过程有所了解。
ELF(Executable and Linkable Format) 文件格式是一种可执行文件和可链接文件格式,它是现代Unix和Linux系统上最常见的二进制文件格式之一,so 库其实就是一个 ELF 文件

ELF 文件格式也比较复杂,我们这里主要关心.plt与.got两个表
- The Global Offset Table/全局偏移量表 (GOT)。简单来说就是在数据段的地址表,假定我们有一些代码段的指令引用一些地址变量,编译器会引用 GOT 表来替代直接引用绝对地址,因为绝对地址在编译期是无法知道的,只有重定位后才会得到 ,GOT 自己本身将会包含函数引用的绝对地址。
- The Procedure Linkage Table/过程链接表 (PLT)。PLT 不同于 GOT,它位于代码段,动态库的每一个外部函数都会在 PLT 中有一条记录,每一条 PLT 记录都是一小段可执行代码。一般来说,外部代码都是在调用 PLT 表里的记录,然后 PLT 的相应记录会负责调用实际的函数。我们一般把这种设定叫作“蹦床”(Trampoline)。
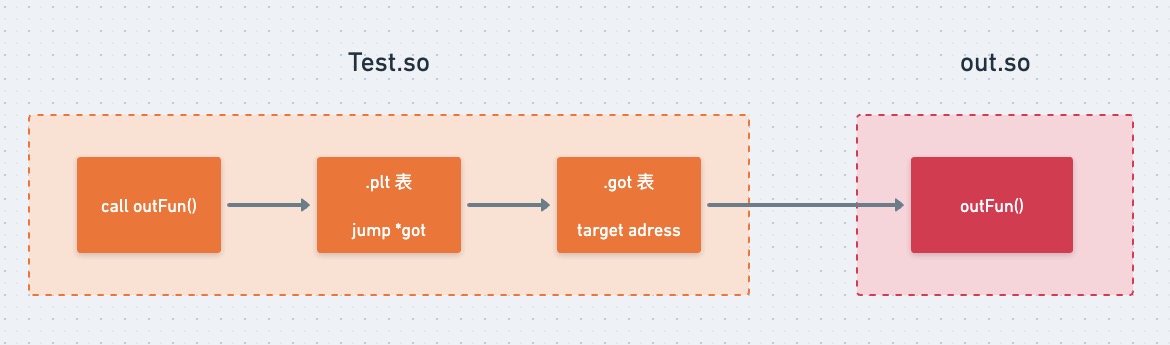
简单来说,对于其它 so 中的函数,在编译期无法确定其地址,只有在运行时才能获取,因此需要查询 GOT 表来查询外部函数的绝对地址。外部库函数的绝对地址在 got 表中的初始值都是 0 ,只有当实际调用这个函数时,Linker 程序才会写入实际的地址。
因此如果我们想要实现 native hook,只需要把 got 表中的目标函数的地址修改为我们自定义的地址即可。
那么在这个过程中,PLT 表的作用又是什么呢?
实际上,在函数调用的过程中,会先跳转到 PLT 表,它位于代码段,每一条 PLT 记录都是一小段可执行代码,这段代码会查询 GOT 表,获取真实地址然后跳转对应的函数
听起来有些多此一举,实际上 PLT 表可以起到延迟绑定的作用,只有当真正调用目标函数时,got 表中才会去绑定真实地址,如果没有调用则不绑定。因为很多函数可能在程序执行完时都不会被用到,那么一开始把所有函数都链接好实际是一种浪费。这就是 PLT 表起到的作用
因此在 So 中调用外部函数的实际过程如下所示:
在了解了 PLT HOOK 的基本原理之后,其实我们可以自己解析 got 表然后替换为自定义的函数地址实现 hook,也可以使用一些已经比较成熟的库
本文后面的实战都是使用 bhook 实现 hook的
Inline Hook
从上面的介绍我们可以看出,PLT Hook 存在一定的局限性,它只能 hook 外部 so 的调用,但如果要 hook 当前的 so 呢?
Hook so 内部调用可以通过 Inline Hook 实现
Inline Hook 是通过在程序运行时动态修改内存中的汇编指令,来改变程序执行流程的一种 Hook 方式,它的基本原理是直接将函数开始处的指令更替为跳转指令,使得原函数直接跳转到 Hook 的目标函数函数,并保留被覆盖的原指令以完成后续再调用回来的目的。

Inline Hook 的基本流程如上所示,主要分为以下几步
- 拷贝原函数的头部两条汇编指令,并覆盖成跳转到自定义函数的指令
- 执行自定义函数,再执行前面被覆盖的两条指令
- 执行后续指令
与 PLT Hook 方式相比,Inline Hook 更加强大,几乎可以 Hook 任何函数,但由于其实现十分复杂,需要直接修改汇编指令,因此会有很多兼容性问题,不太稳定,因此如果想要使用的话推荐直接使用相应的开源库,比如字节开源的:https://github.com/bytedance/android-inline-hook
小结
总得来说,两种 Native Hook 方式各有优劣,可根据实际情况使用
- PLT HooK的优点在于稳定,缺点则在于只能 Hook 外部函数的调用
- Inline Hook的优点在于可以 hook so 内部调用,缺点则在于不够稳定,存在一定的兼容问题
Native Hook 实战
接下来我们通过 Native Hook 技术来实现对 Native 内存申请的监控,主要支持以下功能
- 添加对 malloc, free 函数的 hook,支持统计 so 的内存申请与释放情况
- 当申请超大内存时,支持获取 native 堆栈以定位问题
- 直接获取的 native 堆栈是个 16 进制数组,无法看出有效信息,因此还需要将解析堆栈还原出 so 名与函数信息
Hook 函数
我们这里通过 bhook 库来实现对 malloc, free 函数的 hook,如下所示
void *malloc_proxy(size_t len) {
BYTEHOOK_STACK_SCOPE();
Dl_info callerInfo = {};
if (dladdr(__builtin_return_address(0), &callerInfo)) {
// 统计分配的内存
onMalloc(callerInfo.dli_fname, len);
}
// ...
void *object = BYTEHOOK_CALL_PREV(malloc_proxy, len);
objMap[object] = len;
return object;
}
void free_proxy(void *__ptr) {
BYTEHOOK_STACK_SCOPE();
Dl_info callerInfo = {};
if (dladdr(__builtin_return_address(0), &callerInfo)) {
auto len = objMap.find(__ptr);
// 统计 free的内存
onFree(callerInfo.dli_fname, len->second);
}
return BYTEHOOK_CALL_PREV(free_proxy, __ptr);
}
void hookMemory() {
bytehook_hook_all(nullptr, "malloc", (void *) malloc_proxy,
nullptr,
nullptr);
bytehook_hook_all(nullptr, "free", (void *) free_proxy,
nullptr,
nullptr);
}
hook 的逻辑非常简单,通过调用bytehook_hook_all,指定要hook的方法与代理方法,所有的malloc方法调用都会被代理到malloc_proxy方法,所有的free方法调用也会被代理到free_proxy方法中
然后我们在代理方法中加入 so 分配与回收内存的监控,就可以统计出一个 so 库一共申请了多少内存,释放了多少内存,打印出来的日志如下所示
So /apex/com.android.art/lib64/libart-compiler.so allocated 581632 bytes, freed 2883686 bytes
So /apex/com.android.art/lib64/libc++.so allocated 2779694 bytes, freed 2640 bytes
So /apex/com.android.art/lib64/liblzma.so allocated 9071256 bytes, freed 9071256 bytes
So /apex/com.android.i18n/lib64/libicuuc.so allocated 36428 bytes, freed 1164 bytes
So /apex/com.android.runtime/lib64/bionic/libc.so allocated 33360 bytes, freed 0 bytes
So /apex/com.android.vndk.v30/lib64/libc++.so allocated 10944 bytes, freed 0 bytes
So /data/app/~~6Mf4VQY4K16aFji1rZ4dkg==/com.zj.android.performance-XHR75TrkIVbXU9GfDYgZGg==/lib/arm64/libandroid-performance.so allocated 184549424 bytes, freed 184549424 bytes
So /data/app/~~6Mf4VQY4K16aFji1rZ4dkg==/com.zj.android.performance-XHR75TrkIVbXU9GfDYgZGg==/lib/arm64/libmemory-hook.so allocated 3310960 bytes, freed 2776978 bytes
So /system/lib64/libbinder.so allocated 129408 bytes, freed 462200 bytes
So /system/lib64/libc++.so allocated 14428072 bytes, freed 864 bytes
So /system/lib64/libhwui.so allocated 725687 bytes, freed 11980415 bytes
So /system/lib64/libutils.so allocated 1896281 bytes, freed 2132345 bytes
So /system/lib64/libz.so allocated 565024 bytes, freed 565024 bytes
获取 native 堆栈
除了统计 So 内存使用情况之外,在申请超大内存时,我们也可以获取 native 堆栈以方便定位问题
目前,在 Android 中获取 Native 堆栈的方法基本上都是通过 CFI 来实现的。CFI 代表 Call Frame Information,即帧调用信息。在程序运行时,当 Native 函数执行进入栈指令时,它会将对应指令的信息(即 CFI )写入 so 文件中的 .eh_frame 和 .eh_frame_hdr 段中,这两个段是 so 文件中的段之一。因此,要获取 Native 堆栈,只需要读取这两个段中的数据即可。
在 Android 系统中,我们可以使用 libunwind 库来直接获取 Native 堆栈信息,其底层原理实际上也是通过读取 CFI 来实现的
#include <unwind.h> //引入 unwind 库
struct backtrace_stack {
void **current;
void **end;
};
static _Unwind_Reason_Code unwind_callback(struct _Unwind_Context *context, void *data) {
auto *state = (struct backtrace_stack *) (data);
uintptr_t pc = _Unwind_GetIP(context); // 获取 pc 值,即绝对地址
if (pc) {
if (state->current == state->end) {
return _URC_END_OF_STACK;
} else {
*state->current++ = (void *) (pc);
}
}
return _URC_NO_REASON;
}
static size_t fill_backtraces_buffer(void **buffer, int max) {
struct backtrace_stack stack = {buffer, buffer + max};
_Unwind_Backtrace(unwind_callback, &stack);
return stack.current - buffer;
}
void *malloc_proxy(size_t len) {
// ...
if (len > 80 * 1024 * 1024) {
// 当申请内存大小大于 80M 时获取堆栈
int maxStackSize = 30;
void *buffer[maxStackSize];
int count = fill_backtraces_buffer(buffer, maxStackSize);
dumpBacktrace(buffer, count);
}
// ...
return object;
}
如上所示,当申请内存大小大于 80M 时,我们通过 unwind 来获取堆栈,将将获取的堆栈放入 buffer 数组中
但是我们获得的 buffer 数组只是 16 进制的地址,根本看不出有效信息,如下所示:
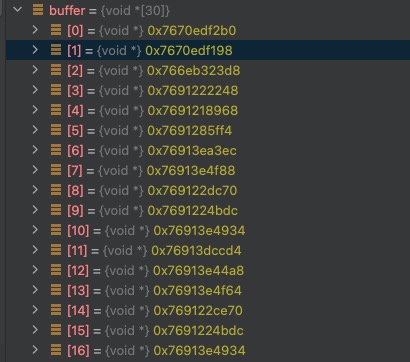
因此我们还要进行下一步,还原堆栈信息
还原堆栈信息
要将16进制的地址堆栈还原成带有效信息的堆栈,通常需要完成以下三个步骤:
- 首先要确认相关的 so 文件名称;
- 接下来需要计算相应的偏移地址;
- 最后,基于带符号表(ELF文件中的一张表,存放了函数、方法、变量等名称符号信息)的so文件,还原指针对应的函数名和行数。
确认 so 文件名称
我们可以通过dladdr函数来查询 so 文件名,函数定义如下
int dladdr ( void * addr , Dl_info * info ) ;
typedef struct {
const char *dli_fname; //地址对应的 so 名
void *dli_fbase; //对应so库的基地址
const char *dli_sname; //如果so库有符号表,这会显示离地址最近的函数名
void *dli_saddr; //符号表中,离地址最近的函数的地址
} Dl_info;
我们将函数地址传入dladdr函数,就可以获取相应的 so 库名称与基地址,如下所示:
void dumpBacktrace(void **buffer, size_t count) {
for (int i = 0; i < count; ++i) {
void *addr = buffer[i];
Dl_info info = {};
if (dladdr(addr, &info)) {
LOG("# %d : %p : %s(%s)(%p)", i, addr, info.dli_fname,
info.dli_sname, info.dli_saddr);
}
}
}
通过dladdr函数获取的堆栈打印如下所示:
# 0 : 0x767174309c : /data/app/~~6Mf4VQY4K16aFji1rZ4dkg==/com.zj.android.performance-XHR75TrkIVbXU9GfDYgZGg==/lib/arm64/libmemory-hook.so(0x2609c)((null))(0x0)
# 1 : 0x7671742ec8 : /data/app/~~6Mf4VQY4K16aFji1rZ4dkg==/com.zj.android.performance-XHR75TrkIVbXU9GfDYgZGg==/lib/arm64/libmemory-hook.so(0x25ec8)(_Z12malloc_proxym)(0x7671742dbc)
# 2 : 0x76712f23d8 : /data/app/~~6Mf4VQY4K16aFji1rZ4dkg==/com.zj.android.performance-XHR75TrkIVbXU9GfDYgZGg==/lib/arm64/libandroid-performance.so(0x203d8)(Java_com_zj_android_performance_jni_NativeLibTest_testMalloc)(0x76712f23a8)
# 3 : 0x7691222248 : /apex/com.android.art/lib64/libart.so(0x222248)((null))(0x0)
# 4 : 0x7691218968 : /apex/com.android.art/lib64/libart.so(0x218968)((null))(0x0)
# 5 : 0x7691285ff4 : /apex/com.android.art/lib64/libart.so(0x285ff4)(_ZN3art9ArtMethod6InvokeEPNS_6ThreadEPjjPNS_6JValueEPKc)(0x7691285f30)
# 6 : 0x76913ea3ec : /apex/com.android.art/lib64/libart.so(0x3ea3ec)(_ZN3art11interpreter34ArtInterpreterToCompiledCodeBridgeEPNS_6ThreadEPNS_9ArtMethodEPNS_11ShadowFrameEtPNS_6JValueE)(0x76913ea254)
# 7 : 0x76913e4f88 : /apex/com.android.art/lib64/libart.so(0x3e4f88)(_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE)(0x76913e4c48)
# 8 : 0x769175fd10 : /apex/com.android.art/lib64/libart.so(0x75fd10)(MterpInvokeVirtual)(0x769175f878)
# 9 : 0x7691203818 : /apex/com.android.art/lib64/libart.so(0x203818)((null))(0x0)
# 10 : 0x769176b3f4 : /apex/com.android.art/lib64/libart.so(
# 11 : 0x7691203998 : /apex/com.android.art/lib64/libart.so(0x203998)((null))(0x0)
# 12 : 0x769176b3f4 : /apex/com.android.art/lib64/libart.so(
# 13 : 0x7691203998 : /apex/com.android.art/lib64/libart.so(0x203998)((null))(0x0)
# 14 : 0x76913dcd30 : /apex/com.android.art/lib64/libart.so(0x3dcd30)((null))(0x0)
malloc 92274688 byte success
可以看出,在有符号表的情况下,so 名与函数名都正确的打印出来了,而对于 libart,由于已经移除了符号表,则显示为 null ,地址也为 0
计算函数偏移地址
通过dladdr函数,我们已经获取了堆栈的 so 名与函数名,那可不可以具体定位到到底是函数的哪一行出现了问题吗?
我们可以通过 NDK 的 addr2line 工具,根据函数偏移地址,获取地址对应的函数名、行号等信息
addr2line -C -f -e xxx.so 函数偏移地址
-C:将低级别的符号名解码为用户级别的名字。
-e:指定需要转换地址的可执行文件名
-f:在显示文件名、行号信息的同时显示函数名。
我们在堆栈中获取的地址是函数的绝对地址,要获取偏移地址减去 so 的基地址就可以了
偏移地址 = 函数的绝对地址 - 库文件的基地址
void dumpBacktrace(void **buffer, size_t count) {
for (int i = 0; i < count; ++i) {
if (dladdr(addr, &info)) {
// 计算偏移地址
const uintptr_t address_relative = (uintptr_t) addr - (uintptr_t) info.dli_fbase;
LOG("# %d : %p : %s(%p)(%s)(%p)", i, addr, info.dli_fname, address_relative,
info.dli_sname, info.dli_saddr);
}
}
}
从上面的日志也可以看出,有问题的Java_com_zj_android_performance_jni_NativeLibTest_testMalloc函数的偏移地址是0x203d8
还原函数名及行号
现在,我们已经得知了函数的偏移地址,接下来就可以使用 addr2line 工具来获取行号了。在 Android 的 NDK 中已经提供了这个工具,位于 /ndk/xxx/toolchains/aarch64-linux-android-4.9/prebuilt/darwin-x86_64/bin 目录中。如果您使用的是 M1 电脑,可以选择 aarch64 目录。
arm-linux-androideabi-addr2line -C -f -e libandroid_performance.so 0x203d8
需要注意的是,这里的 so 必须是带符号表的,因此需要在编译产物中的 native_libs 目录去找(注意不是 stripped_native_libs 目录)
运行以上命令后,得到的结果如下

可以看出,已经定位到了具体的函数名与行号
总结
本文主要介绍了 Native Hook 是什么以及常见实现方案,同时通过一个监控 native 内存的例子进行了实践
在 Android 应用性能优化中,Native Hook 技术广泛应用于内存优化、启动优化等方面,如 bitmap hook、pthread hook、GC 抑制等。因此,如果您希望在相关领域进行技术优化,掌握 Native Hook 技术将是非常有必要的。
参考资料
本文主要是对Android 性能优化小册相关内容的学习实践,感兴趣的同学可以点击查看
源码
本文所有源码可见:https://github.com/RicardoJiang/android-performance