Android 性能优化技术月报 | 2024 年 4 月
每个月都会有一些 Android 性能优化相关的优质内容发布,然而,碎片化阅读使得这些知识难以形成完整体系,且容易被遗忘。为解决这些问题,我决定尝试使用技术月报的形式,总结我在最近一个月内查阅的 Android 性能优化相关的优质内容。
月报的主要内容包括:整理展示我在最近一个月所查阅的 Android 性能优化领域的最新技术动态、精选博客,精选视频等内容。
精选博客
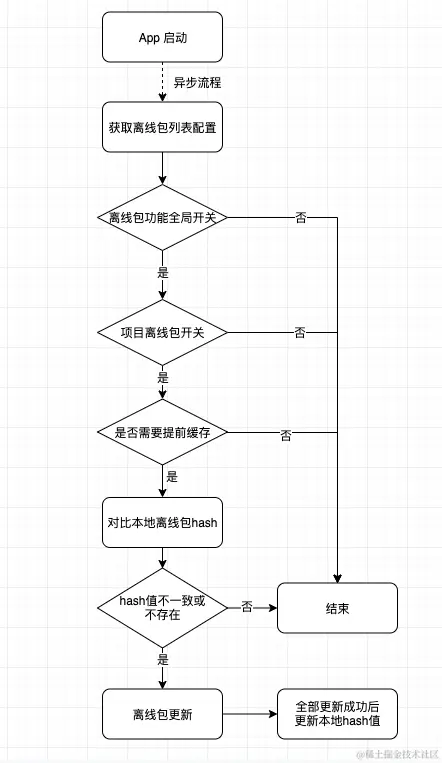
Android 离线加载落地
在使用WebView时,会有一个老生常谈的话题——“WebView加载优化”。那WebView加载优化,一般有几个方向:WebView的预创建和复用,WebView代理请求,WebView的离线加载
离线加载的原理是,拦截WebView的请求,转而在端内构造对应的响应来进行返回。所以,离线加载节省的是请求资源的耗时,加速页面的渲染,主要通过shouldInterceptRequest方法来实现:
public class LocalH5WebHook extends SimpleWebHook {
//... 省略其他代码
public WebResourceResponse shouldInterceptRequest(WebView view, WebResourceRequest request) {
WebResourceResponse webResourceResponse = fetchResource(request);
if (webResourceResponse != null) {
return webResourceResponse;
}
return super.shouldInterceptRequest(view, request);
}
}
低成本的 H5 秒开方案-接口预请求
当我们打开在 APP 内的 H5 页面时,一般会经过原生切页面动画、创建新页面、加载 webview、加载 HTML、请求静态资源并解析、获取首屏数据、渲染内容、下载图片等步骤。
其实在加载的同时,可以利用 APP 在帮助 H5 获取首屏数据,这样在 H5 页面加载完成后,可以直接使用 APP 已请求的首屏数据进行渲染,这样就节省了获取首屏数据的时间。首屏数据接口越慢,该方案的价值就越大。

- 既然我们要利用 APP 来帮助 H5 获取首屏数据,而我们的 H5 页面也不止一个,并且每个页面的参数都不一样。 那第一个要解决的问题就是怎么告诉 APP 在打开那些页面时需要同步请求那些接口,这些接口的入参是什么样的?
- 当 APP 请求完成后,要解决的第二个问题是怎么把请求结果及时通知给 H5 页面,并且防止 H5 页面自身发起重复请求,增加服务端负担?
- 第三个要解决的是如果 H5 修改了代码,更新了参数,而告知 APP 入参的配置还未更新,怎么避免使用旧配置请求的结果?

在使用接口预请求后,绝大部分页面有 200~600ms 的提升,主要使用的 CMS 活动页,安卓提升了 27%,iOS 提升了 43%,平均 FMP 在 900ms 左右(FMP 指的是从用户在 APP 点击 H5 链接到主内容渲染完成的时间)。
AGP8.0 时代的 Transform 实践
众所周知, Transform 接口在 AGP8.0 中已经被移除了, 而以往的大量工程实践都需要使用该接口结合 ASM 对字节码进行操作, 例如: 代码插桩, 代码替换等.那么在 AGP 8.0 中我们该如何适配呢?
Instrumentation 作为 Google 首推的 Transform 替代方案, 只需要实现 AsmClassVisitorFactory 接口即实现对字节码处理.

相较于 Transform 处理流程, Instrumentation 流程免去对中间产物的读写, 并且一定是以 Jar/classes 文件为单位的增量处理, 使得全量编译和增量编译速度都有较大的提升.
通过 Instrumentation 确实能很方便的实现插桩与替换逻辑, 但是理想很丰满,现实很骨感, 很多时候并不能满足需求, 例如:
- 先分析再操作: 在实现 hook 框架时, 通常需要先对工程中的所有 class 进行一次遍历分析后, 再对相关的 class 文件进行字节码操作.
- 输出文件产物: 比如在插桩时在调用 Trace#beginSection 时传入了完整的类名与方法名, 这往往会导致生成的 trace 文件过大. 工程实践中一般会生成 methodId 与类名#方法名的映射, 在 Trace#beginSection 调用时仅仅传入 methodId, 这时就需要在插桩结束后保存当前的 methodId 与类名#方法名的映射文件。
这种情况就需要通过 Artifacts API 处理,如下所示:
variant.artifacts.forScope(ScopedArtifacts.Scope.ALL)
.use(taskProvider)
.toTransform(
ScopedArtifact.CLASSES,
ModifyClassesTask::allJars,
ModifyClassesTask::allDirectories,
ModifyClassesTask::output,
)
GCC 与 LLVM 有什么区别?
GCC(GNU Compiler Collection,GNU 编译器套装),是一套由 GNU 开发的编程语言编译器。GCC 可以分为前端,优化器,后端三部分:
- 前端:解析源代码、检查语法错误、翻译为抽象的语法树
- 优化器:将抽象语法树翻译生成中间代码,并对中间代码进行优化
- 后端:将优化器优化后的中间代码转换为目标机器的代码,通用功能包括指令选择、寄存器分配和指令调度

通过上述架构,GCC 新增支持语言只需要新增一个前端,新增支持目标机器只需要新增一个后端。苹果公司一直使用 GCC 作为官方的编译器。GCC 作为一款开源的编译器,一直做得不错,但 Apple 对编译工具会提出更高的要求。原因主要有以下两点:
- Apple 对 Objective-C 语言(包括后来对 C 语言)新增很多特性,GCC 并没有支持,导致出现版本分叉
- GCC 的三段式模块必须配套使用,很难做到部分重用
因此 Apple 推出了 LLVM,LLVM是三段式编译器优化器+后端的SDK集合,提供了一系列对外接口供开发者调用
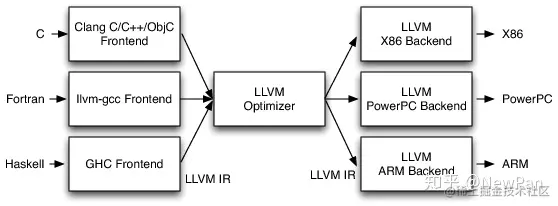
- 前端:支持各种组件的前端(Clang、llvm-gcc、GHC),需要遵守LLVM的规则,输出中间代码LLVM IR
- 优化器:LLVM IR通过一系列分析和优化从而改进代码,然后输入代码生成器生成目标机器码
- 后端:将优化器优化后的中间代码转换为目标机器的代码
LLVM 与其它编译器最大的差别是,它不仅仅是 Compiler Collection,也是 Libraries Collection。LLVM 不仅仅是编译器,也是一个 SDK,LLVM 提供了灵活的代码复用能力,将编译后端的算法封装成为了一个个独立的模块并提供对外接口,而GCC传统编译器耦合很重,很难小粒度复用代码